A Guide To The Methods, Benefits & Problems of The Interpretation of Data

Table of Contents
1) What Is Data Interpretation?
3) Why Data Interpretation Is Important?
5) Data Analysis & Interpretation Problems
6) Data Interpretation Techniques & Methods
Data analysis and interpretation have now taken center stage with the advent of the digital age… and the sheer amount of data can be frightening. In fact, a Digital Universe study found that the total data supply in 2012 was 2.8 trillion gigabytes! Based on that amount of data alone, it is clear the calling card of any successful enterprise in today’s global world will be the ability to analyze complex data, produce actionable insights, and adapt to new market needs… all at the speed of thought.
Business dashboards are the digital age tools for big data. Capable of displaying key performance indicators (KPIs) for both quantitative and qualitative data analyses, they are ideal for making the fast-paced and data-driven market decisions that push today’s industry leaders to sustainable success. Through the art of streamlined visual communication, data dashboards permit businesses to engage in real-time and informed decision-making and are key instruments in data interpretation. First of all, let’s find a definition to understand what lies behind this practice.
What Is Data Interpretation?
Data interpretation refers to the process of using diverse analytical methods to review data and arrive at relevant conclusions. The interpretation of data helps researchers to categorize, manipulate, and summarize the information in order to answer critical questions.
The importance of data interpretation is evident, and this is why it needs to be done properly. Data is very likely to arrive from multiple sources and has a tendency to enter the analysis process with haphazard ordering. Data analysis tends to be extremely subjective. That is to say, the nature and goal of interpretation will vary from business to business, likely correlating to the type of data being analyzed. While there are several types of processes that are implemented based on the nature of individual data, the two broadest and most common categories are “quantitative and qualitative analysis.”
Yet, before any serious data interpretation inquiry can begin, it should be understood that visual presentations of data findings are irrelevant unless a sound decision is made regarding measurement scales. Before any serious data analysis can begin, the measurement scale must be decided for the data as this will have a long-term impact on data interpretation ROI. The varying scales include:
- Nominal Scale: non-numeric categories that cannot be ranked or compared quantitatively. Variables are exclusive and exhaustive.
- Ordinal Scale: exclusive categories that are exclusive and exhaustive but with a logical order. Quality ratings and agreement ratings are examples of ordinal scales (i.e., good, very good, fair, etc., OR agree, strongly agree, disagree, etc.).
- Interval: a measurement scale where data is grouped into categories with orderly and equal distances between the categories. There is always an arbitrary zero point.
- Ratio: contains features of all three.
For a more in-depth review of scales of measurement, read our article on data analysis questions. Once measurement scales have been selected, it is time to select which of the two broad interpretation processes will best suit your data needs. Let’s take a closer look at those specific methods and possible data interpretation problems.
How To Interpret Data? Top Methods & Techniques

When interpreting data, an analyst must try to discern the differences between correlation, causation, and coincidences, as well as many other biases – but he also has to consider all the factors involved that may have led to a result. There are various data interpretation types and methods one can use to achieve this.
The interpretation of data is designed to help people make sense of numerical data that has been collected, analyzed, and presented. Having a baseline method for interpreting data will provide your analyst teams with a structure and consistent foundation. Indeed, if several departments have different approaches to interpreting the same data while sharing the same goals, some mismatched objectives can result. Disparate methods will lead to duplicated efforts, inconsistent solutions, wasted energy, and inevitably – time and money. In this part, we will look at the two main methods of interpretation of data: qualitative and quantitative analysis.
Qualitative Data Interpretation
Qualitative data analysis can be summed up in one word – categorical. With this type of analysis, data is not described through numerical values or patterns but through the use of descriptive context (i.e., text). Typically, narrative data is gathered by employing a wide variety of person-to-person techniques. These techniques include:
- Observations: detailing behavioral patterns that occur within an observation group. These patterns could be the amount of time spent in an activity, the type of activity, and the method of communication employed.
- Focus groups: Group people and ask them relevant questions to generate a collaborative discussion about a research topic.
- Secondary Research: much like how patterns of behavior can be observed, various types of documentation resources can be coded and divided based on the type of material they contain.
- Interviews: one of the best collection methods for narrative data. Inquiry responses can be grouped by theme, topic, or category. The interview approach allows for highly focused data segmentation.
A key difference between qualitative and quantitative analysis is clearly noticeable in the interpretation stage. The first one is widely open to interpretation and must be “coded” so as to facilitate the grouping and labeling of data into identifiable themes. As person-to-person data collection techniques can often result in disputes pertaining to proper analysis, qualitative data analysis is often summarized through three basic principles: notice things, collect things, and think about things.
After qualitative data has been collected through transcripts, questionnaires, audio and video recordings, or the researcher’s notes, it is time to interpret it. For that purpose, there are some common methods used by researchers and analysts.
- Content analysis: As its name suggests, this is a research method used to identify frequencies and recurring words, subjects, and concepts in image, video, or audio content. It transforms qualitative information into quantitative data to help discover trends and conclusions that will later support important research or business decisions. This method is often used by marketers to understand brand sentiment from the mouths of customers themselves. Through that, they can extract valuable information to improve their products and services. It is recommended to use content analytics tools for this method as manually performing it is very time-consuming and can lead to human error or subjectivity issues. Having a clear goal in mind before diving into it is another great practice for avoiding getting lost in the fog.
- Thematic analysis: This method focuses on analyzing qualitative data, such as interview transcripts, survey questions, and others, to identify common patterns and separate the data into different groups according to found similarities or themes. For example, imagine you want to analyze what customers think about your restaurant. For this purpose, you do a thematic analysis on 1000 reviews and find common themes such as “fresh food”, “cold food”, “small portions”, “friendly staff”, etc. With those recurring themes in hand, you can extract conclusions about what could be improved or enhanced based on your customer’s experiences. Since this technique is more exploratory, be open to changing your research questions or goals as you go.
- Narrative analysis: A bit more specific and complicated than the two previous methods, it is used to analyze stories and discover their meaning. These stories can be extracted from testimonials, case studies, and interviews, as these formats give people more space to tell their experiences. Given that collecting this kind of data is harder and more time-consuming, sample sizes for narrative analysis are usually smaller, which makes it harder to reproduce its findings. However, it is still a valuable technique for understanding customers' preferences and mindsets.
- Discourse analysis: This method is used to draw the meaning of any type of visual, written, or symbolic language in relation to a social, political, cultural, or historical context. It is used to understand how context can affect how language is carried out and understood. For example, if you are doing research on power dynamics, using discourse analysis to analyze a conversation between a janitor and a CEO and draw conclusions about their responses based on the context and your research questions is a great use case for this technique. That said, like all methods in this section, discourse analytics is time-consuming as the data needs to be analyzed until no new insights emerge.
- Grounded theory analysis: The grounded theory approach aims to create or discover a new theory by carefully testing and evaluating the data available. Unlike all other qualitative approaches on this list, grounded theory helps extract conclusions and hypotheses from the data instead of going into the analysis with a defined hypothesis. This method is very popular amongst researchers, analysts, and marketers as the results are completely data-backed, providing a factual explanation of any scenario. It is often used when researching a completely new topic or with little knowledge as this space to start from the ground up.
Quantitative Data Interpretation
If quantitative data interpretation could be summed up in one word (and it really can’t), that word would be “numerical.” There are few certainties when it comes to data analysis, but you can be sure that if the research you are engaging in has no numbers involved, it is not quantitative research, as this analysis refers to a set of processes by which numerical data is analyzed. More often than not, it involves the use of statistical modeling such as standard deviation, mean, and median. Let’s quickly review the most common statistical terms:
- Mean: A mean represents a numerical average for a set of responses. When dealing with a data set (or multiple data sets), a mean will represent the central value of a specific set of numbers. It is the sum of the values divided by the number of values within the data set. Other terms that can be used to describe the concept are arithmetic mean, average, and mathematical expectation.
- Standard deviation: This is another statistical term commonly used in quantitative analysis. Standard deviation reveals the distribution of the responses around the mean. It describes the degree of consistency within the responses; together with the mean, it provides insight into data sets.
- Frequency distribution: This is a measurement gauging the rate of a response appearance within a data set. When using a survey, for example, frequency distribution, it can determine the number of times a specific ordinal scale response appears (i.e., agree, strongly agree, disagree, etc.). Frequency distribution is extremely keen in determining the degree of consensus among data points.
Typically, quantitative data is measured by visually presenting correlation tests between two or more variables of significance. Different processes can be used together or separately, and comparisons can be made to ultimately arrive at a conclusion. Other signature interpretation processes of quantitative data include:
- Regression analysis: Essentially, it uses historical data to understand the relationship between a dependent variable and one or more independent variables. Knowing which variables are related and how they developed in the past allows you to anticipate possible outcomes and make better decisions going forward. For example, if you want to predict your sales for next month, you can use regression to understand what factors will affect them, such as products on sale and the launch of a new campaign, among many others.
- Cohort analysis: This method identifies groups of users who share common characteristics during a particular time period. In a business scenario, cohort analysis is commonly used to understand customer behaviors. For example, a cohort could be all users who have signed up for a free trial on a given day. An analysis would be carried out to see how these users behave, what actions they carry out, and how their behavior differs from other user groups.
- Predictive analysis: As its name suggests, the predictive method aims to predict future developments by analyzing historical and current data. Powered by technologies such as artificial intelligence and machine learning, predictive analytics practices enable businesses to identify patterns or potential issues and plan informed strategies in advance.
- Prescriptive analysis: Also powered by predictions, the prescriptive method uses techniques such as graph analysis, complex event processing, and neural networks, among others, to try to unravel the effect that future decisions will have in order to adjust them before they are actually made. This helps businesses to develop responsive, practical business strategies.
- Conjoint analysis: Typically applied to survey analysis, the conjoint approach is used to analyze how individuals value different attributes of a product or service. This helps researchers and businesses to define pricing, product features, packaging, and many other attributes. A common use is menu-based conjoint analysis, in which individuals are given a “menu” of options from which they can build their ideal concept or product. Through this, analysts can understand which attributes they would pick above others and drive conclusions.
- Cluster analysis: Last but not least, the cluster is a method used to group objects into categories. Since there is no target variable when using cluster analysis, it is a useful method to find hidden trends and patterns in the data. In a business context, clustering is used for audience segmentation to create targeted experiences. In market research, it is often used to identify age groups, geographical information, and earnings, among others.
Now that we have seen how to interpret data, let's move on and ask ourselves some questions: What are some of the benefits of data interpretation? Why do all industries engage in data research and analysis? These are basic questions, but they often don’t receive adequate attention.
Use our 14-days free trial & start extracting insights from your data!
Why Data Interpretation Is Important

The purpose of collection and interpretation is to acquire useful and usable information and to make the most informed decisions possible. From businesses to newlyweds researching their first home, data collection and interpretation provide limitless benefits for a wide range of institutions and individuals.
Data analysis and interpretation, regardless of the method and qualitative/quantitative status, may include the following characteristics:
- Data identification and explanation
- Comparing and contrasting data
- Identification of data outliers
- Future predictions
Data analysis and interpretation, in the end, help improve processes and identify problems. It is difficult to grow and make dependable improvements without, at the very least, minimal data collection and interpretation. What is the keyword? Dependable. Vague ideas regarding performance enhancement exist within all institutions and industries. Yet, without proper research and analysis, an idea is likely to remain in a stagnant state forever (i.e., minimal growth). So… what are a few of the business benefits of digital age data analysis and interpretation? Let’s take a look!
1) Informed decision-making: A decision is only as good as the knowledge that formed it. Informed data decision-making can potentially set industry leaders apart from the rest of the market pack. Studies have shown that companies in the top third of their industries are, on average, 5% more productive and 6% more profitable when implementing informed data decision-making processes. Most decisive actions will arise only after a problem has been identified or a goal defined. Data analysis should include identification, thesis development, and data collection, followed by data communication.
If institutions only follow that simple order, one that we should all be familiar with from grade school science fairs, then they will be able to solve issues as they emerge in real-time. Informed decision-making has a tendency to be cyclical. This means there is really no end, and eventually, new questions and conditions arise within the process that need to be studied further. The monitoring of data results will inevitably return the process to the start with new data and sights.
2) Anticipating needs with trends identification: data insights provide knowledge, and knowledge is power. The insights obtained from market and consumer data analyses have the ability to set trends for peers within similar market segments. A perfect example of how data analytics can impact trend prediction is evidenced in the music identification application Shazam. The application allows users to upload an audio clip of a song they like but can’t seem to identify. Users make 15 million song identifications a day. With this data, Shazam has been instrumental in predicting future popular artists.
When industry trends are identified, they can then serve a greater industry purpose. For example, the insights from Shazam’s monitoring benefits not only Shazam in understanding how to meet consumer needs but also grant music executives and record label companies an insight into the pop-culture scene of the day. Data gathering and interpretation processes can allow for industry-wide climate prediction and result in greater revenue streams across the market. For this reason, all institutions should follow the basic data cycle of collection, interpretation, decision-making, and monitoring.
3) Cost efficiency: Proper implementation of analytics processes can provide businesses with profound cost advantages within their industries. A recent data study performed by Deloitte vividly demonstrates this in finding that data analysis ROI is driven by efficient cost reductions. Often, this benefit is overlooked because making money is typically viewed as “sexier” than saving money. Yet, sound data analyses have the ability to alert management to cost-reduction opportunities without any significant exertion of effort on the part of human capital.
A great example of the potential for cost efficiency through data analysis is Intel. Prior to 2012, Intel would conduct over 19,000 manufacturing function tests on their chips before they could be deemed acceptable for release. To cut costs and reduce test time, Intel implemented predictive data analyses. By using historical and current data, Intel now avoids testing each chip 19,000 times by focusing on specific and individual chip tests. After its implementation in 2012, Intel saved over $3 million in manufacturing costs. Cost reduction may not be as “sexy” as data profit, but as Intel proves, it is a benefit of data analysis that should not be neglected.
4) Clear foresight: companies that collect and analyze their data gain better knowledge about themselves, their processes, and their performance. They can identify performance challenges when they arise and take action to overcome them. Data interpretation through visual representations lets them process their findings faster and make better-informed decisions on the company's future.
Key Data Interpretation Skills You Should Have
Just like any other process, data interpretation and analysis require researchers or analysts to have some key skills to be able to perform successfully. It is not enough just to apply some methods and tools to the data; the person who is managing it needs to be objective and have a data-driven mind, among other skills.
It is a common misconception to think that the required skills are mostly number-related. While data interpretation is heavily analytically driven, it also requires communication and narrative skills, as the results of the analysis need to be presented in a way that is easy to understand for all types of audiences.
Luckily, with the rise of self-service tools and AI-driven technologies, data interpretation is no longer segregated for analysts only. However, the topic still remains a big challenge for businesses that make big investments in data and tools to support it, as the interpretation skills required are still lacking. It is worthless to put massive amounts of money into extracting information if you are not going to be able to interpret what that information is telling you. For that reason, below we list the top 5 data interpretation skills your employees or researchers should have to extract the maximum potential from the data.
- Data Literacy: The first and most important skill to have is data literacy. This means having the ability to understand, work, and communicate with data. It involves knowing the types of data sources, methods, and ethical implications of using them. In research, this skill is often a given. However, in a business context, there might be many employees who are not comfortable with data. The issue is the interpretation of data can not be solely responsible for the data team, as it is not sustainable in the long run. Experts advise business leaders to carefully assess the literacy level across their workforce and implement training instances to ensure everyone can interpret their data.
- Data Tools: The data interpretation and analysis process involves using various tools to collect, clean, store, and analyze the data. The complexity of the tools varies depending on the type of data and the analysis goals. Going from simple ones like Excel to more complex ones like databases, such as SQL, or programming languages, such as R or Python. It also involves visual analytics tools to bring the data to life through the use of graphs and charts. Managing these tools is a fundamental skill as they make the process faster and more efficient. As mentioned before, most modern solutions are now self-service, enabling less technical users to use them without problem.
- Critical Thinking: Another very important skill is to have critical thinking. Data hides a range of conclusions, trends, and patterns that must be discovered. It is not just about comparing numbers; it is about putting a story together based on multiple factors that will lead to a conclusion. Therefore, having the ability to look further from what is right in front of you is an invaluable skill for data interpretation.
- Data Ethics: In the information age, being aware of the legal and ethical responsibilities that come with the use of data is of utmost importance. In short, data ethics involves respecting the privacy and confidentiality of data subjects, as well as ensuring accuracy and transparency for data usage. It requires the analyzer or researcher to be completely objective with its interpretation to avoid any biases or discrimination. Many countries have already implemented regulations regarding the use of data, including the GDPR or the ACM Code Of Ethics. Awareness of these regulations and responsibilities is a fundamental skill that anyone working in data interpretation should have.
- Domain Knowledge: Another skill that is considered important when interpreting data is to have domain knowledge. As mentioned before, data hides valuable insights that need to be uncovered. To do so, the analyst needs to know about the industry or domain from which the information is coming and use that knowledge to explore it and put it into a broader context. This is especially valuable in a business context, where most departments are now analyzing data independently with the help of a live dashboard instead of relying on the IT department, which can often overlook some aspects due to a lack of expertise in the topic.
Common Data Analysis And Interpretation Problems

The oft-repeated mantra of those who fear data advancements in the digital age is “big data equals big trouble.” While that statement is not accurate, it is safe to say that certain data interpretation problems or “pitfalls” exist and can occur when analyzing data, especially at the speed of thought. Let’s identify some of the most common data misinterpretation risks and shed some light on how they can be avoided:
1) Correlation mistaken for causation: our first misinterpretation of data refers to the tendency of data analysts to mix the cause of a phenomenon with correlation. It is the assumption that because two actions occurred together, one caused the other. This is inaccurate, as actions can occur together, absent a cause-and-effect relationship.
- Digital age example: assuming that increased revenue results from increased social media followers… there might be a definitive correlation between the two, especially with today’s multi-channel purchasing experiences. But that does not mean an increase in followers is the direct cause of increased revenue. There could be both a common cause and an indirect causality.
- Remedy: attempt to eliminate the variable you believe to be causing the phenomenon.
2) Confirmation bias: our second problem is data interpretation bias. It occurs when you have a theory or hypothesis in mind but are intent on only discovering data patterns that support it while rejecting those that do not.
- Digital age example: your boss asks you to analyze the success of a recent multi-platform social media marketing campaign. While analyzing the potential data variables from the campaign (one that you ran and believe performed well), you see that the share rate for Facebook posts was great, while the share rate for Twitter Tweets was not. Using only Facebook posts to prove your hypothesis that the campaign was successful would be a perfect manifestation of confirmation bias.
- Remedy: as this pitfall is often based on subjective desires, one remedy would be to analyze data with a team of objective individuals. If this is not possible, another solution is to resist the urge to make a conclusion before data exploration has been completed. Remember to always try to disprove a hypothesis, not prove it.
3) Irrelevant data: the third data misinterpretation pitfall is especially important in the digital age. As large data is no longer centrally stored and as it continues to be analyzed at the speed of thought, it is inevitable that analysts will focus on data that is irrelevant to the problem they are trying to correct.
- Digital age example: in attempting to gauge the success of an email lead generation campaign, you notice that the number of homepage views directly resulting from the campaign increased, but the number of monthly newsletter subscribers did not. Based on the number of homepage views, you decide the campaign was a success when really it generated zero leads.
- Remedy: proactively and clearly frame any data analysis variables and KPIs prior to engaging in a data review. If the metric you use to measure the success of a lead generation campaign is newsletter subscribers, there is no need to review the number of homepage visits. Be sure to focus on the data variable that answers your question or solves your problem and not on irrelevant data.
4) Truncating an Axes: When creating a graph to start interpreting the results of your analysis, it is important to keep the axes truthful and avoid generating misleading visualizations. Starting the axes in a value that doesn’t portray the actual truth about the data can lead to false conclusions.
- Digital age example: In the image below, we can see a graph from Fox News in which the Y-axes start at 34%, making it seem that the difference between 35% and 39.6% is way higher than it actually is. This could lead to a misinterpretation of the tax rate changes.
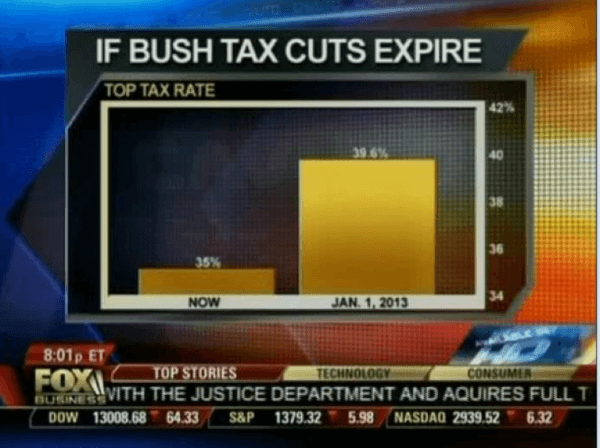
*Source: www.venngage.com*
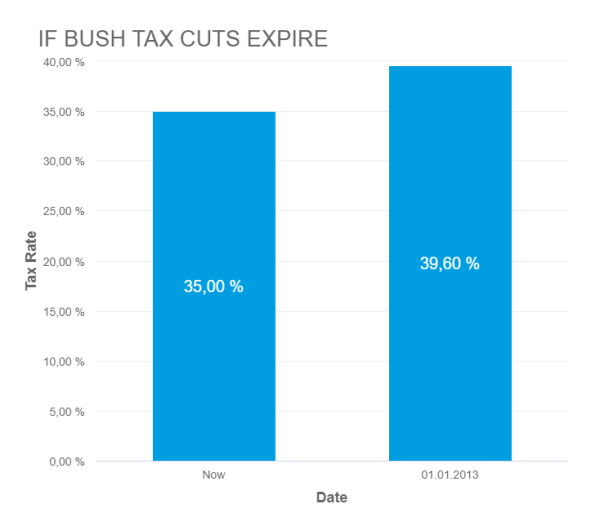
- Remedy: Be careful with how your data is visualized. Be respectful and realistic with axes to avoid misinterpretation of your data. See below how the Fox News chart looks when using the correct axis values. This chart was created with datapine's modern online data visualization tool.
5) (Small) sample size: Another common problem is using a small sample size. Logically, the bigger the sample size, the more accurate and reliable the results. However, this also depends on the size of the effect of the study. For example, the sample size in a survey about the quality of education will not be the same as for one about people doing outdoor sports in a specific area.
- Digital age example: Imagine you ask 30 people a question, and 29 answer “yes,” resulting in 95% of the total. Now imagine you ask the same question to 1000, and 950 of them answer “yes,” which is again 95%. While these percentages might look the same, they certainly do not mean the same thing, as a 30-person sample size is not a significant number to establish a truthful conclusion.
- Remedy: Researchers say that in order to determine the correct sample size to get truthful and meaningful results, it is necessary to define a margin of error that will represent the maximum amount they want the results to deviate from the statistical mean. Paired with this, they need to define a confidence level that should be between 90 and 99%. With these two values in hand, researchers can calculate an accurate sample size for their studies.
6) Reliability, subjectivity, and generalizability: When performing qualitative analysis, researchers must consider practical and theoretical limitations when interpreting the data. In some cases, this type of research can be considered unreliable because of uncontrolled factors that might or might not affect the results. This is paired with the fact that the researcher has a primary role in the interpretation process, meaning he or she decides what is relevant and what is not, and as we know, interpretations can be very subjective.
Generalizability is also an issue that researchers face when dealing with qualitative analysis. As mentioned in the point about having a small sample size, it is difficult to draw conclusions that are 100% representative because the results might be biased or unrepresentative of a wider population.
While these factors are mostly present in qualitative research, they can also affect the quantitative analysis. For example, when choosing which KPIs to portray and how to portray them, analysts can also be biased and represent them in a way that benefits their analysis.
- Digital age example: Biased questions in a survey are a great example of reliability and subjectivity issues. Imagine you are sending a survey to your clients to see how satisfied they are with your customer service with this question: “How amazing was your experience with our customer service team?”. Here, we can see that this question clearly influences the response of the individual by putting the word “amazing” on it.
- Remedy: A solution to avoid these issues is to keep your research honest and neutral. Keep the wording of the questions as objective as possible. For example: “On a scale of 1-10, how satisfied were you with our customer service team?”. This does not lead the respondent to any specific answer, meaning the results of your survey will be reliable.
Use our 14-days free trial & start extracting insights from your data!
Data Interpretation Best Practices & Tips
Data analysis and interpretation are critical to developing sound conclusions and making better-informed decisions. As we have seen with this article, there is an art and science to the interpretation of data. To help you with this purpose, we will list a few relevant techniques, methods, and tricks you can implement for a successful data management process.
As mentioned at the beginning of this post, the first step to interpreting data in a successful way is to identify the type of analysis you will perform and apply the methods respectively. Clearly differentiate between qualitative (observe, document, and interview notice, collect and think about things) and quantitative analysis (you lead research with a lot of numerical data to be analyzed through various statistical methods).
1) Ask the right data interpretation questions
The first data interpretation technique is to define a clear baseline for your work. This can be done by answering some critical questions that will serve as a useful guideline to start. Some of them include: what are the goals and objectives of my analysis? What type of data interpretation method will I use? Who will use this data in the future? And most importantly, what general question am I trying to answer?
Once all this information has been defined, you will be ready for the next step: collecting your data.
2) Collect and assimilate your data
Now that a clear baseline has been established, it is time to collect the information you will use. Always remember that your methods for data collection will vary depending on what type of analysis method you use, which can be qualitative or quantitative. Based on that, relying on professional online data analysis tools to facilitate the process is a great practice in this regard, as manually collecting and assessing raw data is not only very time-consuming and expensive but is also at risk of errors and subjectivity.
Once your data is collected, you need to carefully assess it to understand if the quality is appropriate to be used during a study. This means, is the sample size big enough? Were the procedures used to collect the data implemented correctly? Is the date range from the data correct? If coming from an external source, is it a trusted and objective one?
With all the needed information in hand, you are ready to start the interpretation process, but first, you need to visualize your data.
3) Use the right data visualization type
Data visualizations such as business graphs, charts, and tables are fundamental to successfully interpreting data. This is because data visualization via interactive charts and graphs makes the information more understandable and accessible. As you might be aware, there are different types of visualizations you can use, but not all of them are suitable for any analysis purpose. Using the wrong graph can lead to misinterpretation of your data, so it’s very important to carefully pick the right visual for it. Let’s look at some use cases of common data visualizations.
- Bar chart: One of the most used chart types, the bar chart uses rectangular bars to show the relationship between 2 or more variables. There are different types of bar charts for different interpretations, including the horizontal bar chart, column bar chart, and stacked bar chart.
- Line chart: Most commonly used to show trends, acceleration or decelerations, and volatility, the line chart aims to show how data changes over a period of time, for example, sales over a year. A few tips to keep this chart ready for interpretation are not using many variables that can overcrowd the graph and keeping your axis scale close to the highest data point to avoid making the information hard to read.
- Pie chart: Although it doesn’t do a lot in terms of analysis due to its uncomplex nature, pie charts are widely used to show the proportional composition of a variable. Visually speaking, showing a percentage in a bar chart is way more complicated than showing it in a pie chart. However, this also depends on the number of variables you are comparing. If your pie chart needs to be divided into 10 portions, then it is better to use a bar chart instead.
- Tables: While they are not a specific type of chart, tables are widely used when interpreting data. Tables are especially useful when you want to portray data in its raw format. They give you the freedom to easily look up or compare individual values while also displaying grand totals.
With the use of data visualizations becoming more and more critical for businesses’ analytical success, many tools have emerged to help users visualize their data in a cohesive and interactive way. One of the most popular ones is the use of BI dashboards. These visual tools provide a centralized view of various graphs and charts that paint a bigger picture of a topic. We will discuss the power of dashboards for an efficient data interpretation practice in the next portion of this post. If you want to learn more about different types of graphs and charts, take a look at our complete guide on the topic.
4) Start interpreting
After the tedious preparation part, you can start extracting conclusions from your data. As mentioned many times throughout the post, the way you decide to interpret the data will solely depend on the methods you initially decided to use. If you had initial research questions or hypotheses, then you should look for ways to prove their validity. If you are going into the data with no defined hypothesis, then start looking for relationships and patterns that will allow you to extract valuable conclusions from the information.
During the process of interpretation, stay curious and creative, dig into the data, and determine if there are any other critical questions that should be asked. If any new questions arise, you need to assess if you have the necessary information to answer them. Being able to identify if you need to dedicate more time and resources to the research is a very important step. No matter if you are studying customer behaviors or a new cancer treatment, the findings from your analysis may dictate important decisions in the future. Therefore, taking the time to really assess the information is key. For that purpose, data interpretation software proves to be very useful.
5) Keep your interpretation objective
As mentioned above, objectivity is one of the most important data interpretation skills but also one of the hardest. Being the person closest to the investigation, it is easy to become subjective when looking for answers in the data. A good way to stay objective is to show the information related to the study to other people, for example, research partners or even the people who will use your findings once they are done. This can help avoid confirmation bias and any reliability issues with your interpretation.
Remember, using a visualization tool such as a modern dashboard will make the interpretation process way easier and more efficient as the data can be navigated and manipulated in an easy and organized way. And not just that, using a dashboard tool to present your findings to a specific audience will make the information easier to understand and the presentation way more engaging thanks to the visual nature of these tools.
6) Mark your findings and draw conclusions
Findings are the observations you extracted from your data. They are the facts that will help you drive deeper conclusions about your research. For example, findings can be trends and patterns you found during your interpretation process. To put your findings into perspective, you can compare them with other resources that use similar methods and use them as benchmarks.
Reflect on your own thinking and reasoning and be aware of the many pitfalls data analysis and interpretation carry—correlation versus causation, subjective bias, false information, inaccurate data, etc. Once you are comfortable with interpreting the data, you will be ready to develop conclusions, see if your initial questions were answered, and suggest recommendations based on them.
Interpretation of Data: The Use of Dashboards Bridging The Gap
As we have seen, quantitative and qualitative methods are distinct types of data interpretation and analysis. Both offer a varying degree of return on investment (ROI) regarding data investigation, testing, and decision-making. But how do you mix the two and prevent a data disconnect? The answer is professional data dashboards.
For a few years now, dashboards have become invaluable tools to visualize and interpret data. These tools offer a centralized and interactive view of data and provide the perfect environment for exploration and extracting valuable conclusions. They bridge the quantitative and qualitative information gap by unifying all the data in one place with the help of stunning visuals.
Not only that, but these powerful tools offer a large list of benefits, and we will discuss some of them below.
1) Connecting and blending data. With today’s pace of innovation, it is no longer feasible (nor desirable) to have bulk data centrally located. As businesses continue to globalize and borders continue to dissolve, it will become increasingly important for businesses to possess the capability to run diverse data analyses absent the limitations of location. Data dashboards decentralize data without compromising on the necessary speed of thought while blending both quantitative and qualitative data. Whether you want to measure customer trends or organizational performance, you now have the capability to do both without the need for a singular selection.
2) Mobile Data. Related to the notion of “connected and blended data” is that of mobile data. In today’s digital world, employees are spending less time at their desks and simultaneously increasing production. This is made possible because mobile solutions for analytical tools are no longer standalone. Today, mobile analysis applications seamlessly integrate with everyday business tools. In turn, both quantitative and qualitative data are now available on-demand where they’re needed, when they’re needed, and how they’re needed via interactive online dashboards.
3) Visualization. Data dashboards merge the data gap between qualitative and quantitative data interpretation methods through the science of visualization. Dashboard solutions come “out of the box” and are well-equipped to create easy-to-understand data demonstrations. Modern online data visualization tools provide a variety of color and filter patterns, encourage user interaction, and are engineered to help enhance future trend predictability. All of these visual characteristics make for an easy transition among data methods – you only need to find the right types of data visualization to tell your data story the best way possible.
4) Collaboration. Whether in a business environment or a research project, collaboration is key in data interpretation and analysis. Dashboards are online tools that can be easily shared through a password-protected URL or automated email. Through them, users can collaborate and communicate through the data in an efficient way. Eliminating the need for infinite files with lost updates. Tools such as datapine offer real-time updates, meaning your dashboards will update on their own as soon as new information is available.
Examples Of Data Interpretation In Business
To give you an idea of how a dashboard can fulfill the need to bridge quantitative and qualitative analysis and help in understanding how to interpret data in research thanks to visualization, below, we will discuss three valuable examples to put their value into perspective.
1. Customer Satisfaction Dashboard
This market research dashboard brings together both qualitative and quantitative data that are knowledgeably analyzed and visualized in a meaningful way that everyone can understand, thus empowering any viewer to interpret it. Let’s explore it below.
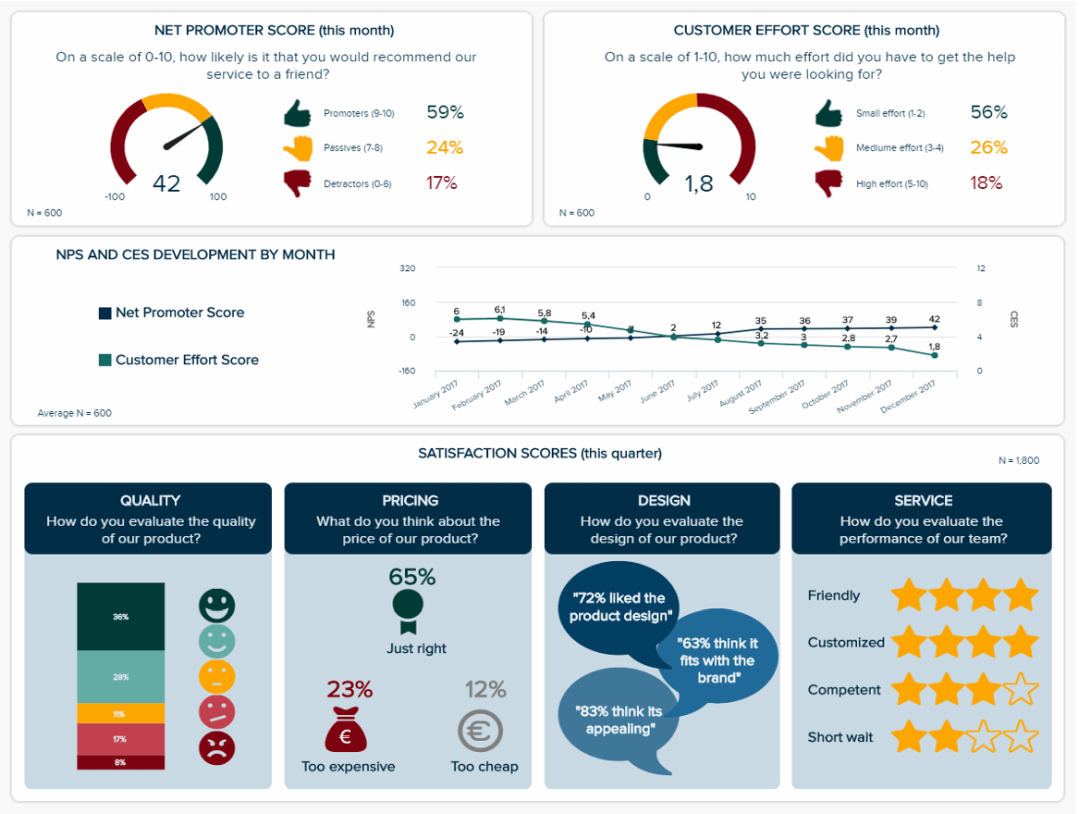
**click to enlarge**
The value of this template lies in its highly visual nature. As mentioned earlier, visuals make the interpretation process way easier and more efficient. Having critical pieces of data represented with colorful and interactive icons and graphs makes it possible to uncover insights at a glance. For example, the colors green, yellow, and red on the charts for the NPS and the customer effort score allow us to conclude that most respondents are satisfied with this brand with a short glance. A further dive into the line chart below can help us dive deeper into this conclusion, as we can see both metrics developed positively in the past 6 months.
The bottom part of the template provides visually stunning representations of different satisfaction scores for quality, pricing, design, and service. By looking at these, we can conclude that, overall, customers are satisfied with this company in most areas.
2. Brand Analysis Dashboard
Next, in our list of data interpretation examples, we have a template that shows the answers to a survey on awareness for Brand D. The sample size is listed on top to get a perspective of the data, which is represented using interactive charts and graphs.
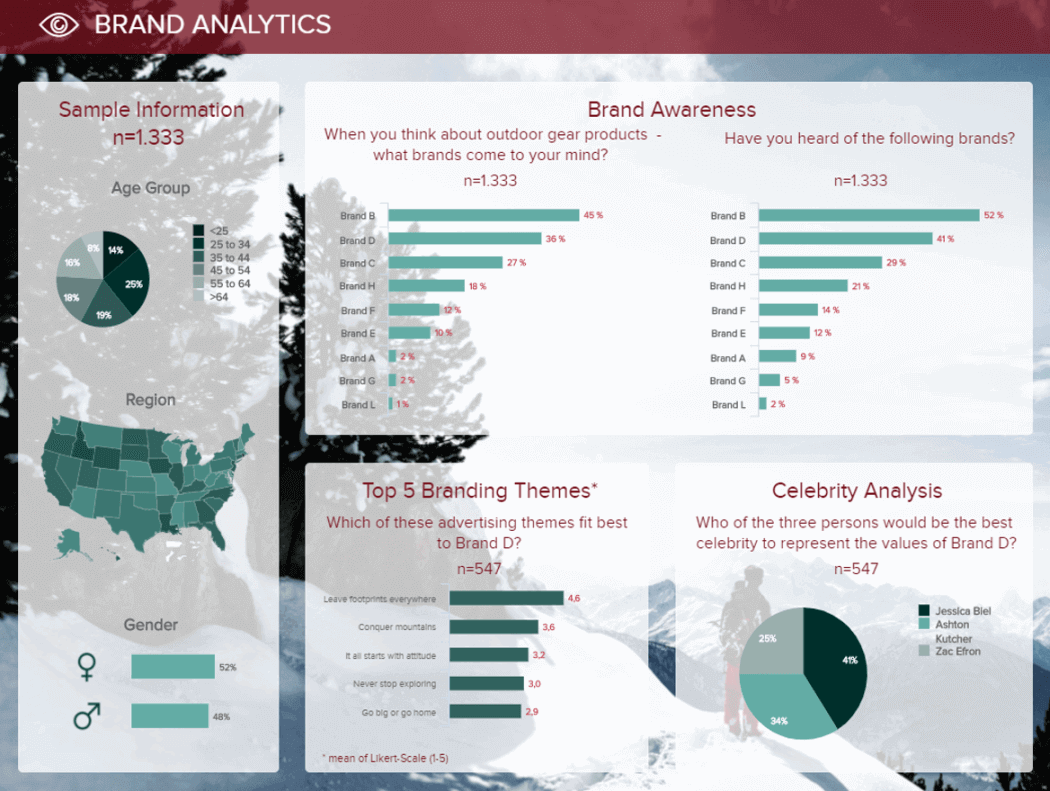
**click to enlarge**
When interpreting information, context is key to understanding it correctly. For that reason, the dashboard starts by offering insights into the demographics of the surveyed audience. In general, we can see ages and gender are diverse. Therefore, we can conclude these brands are not targeting customers from a specified demographic, an important aspect to put the surveyed answers into perspective.
Looking at the awareness portion, we can see that brand B is the most popular one, with brand D coming second on both questions. This means brand D is not doing wrong, but there is still room for improvement compared to brand B. To see where brand D could improve, the researcher could go into the bottom part of the dashboard and consult the answers for branding themes and celebrity analysis. These are important as they give clear insight into what people and messages the audience associates with brand D. This is an opportunity to exploit these topics in different ways and achieve growth and success.
3. Product Innovation Dashboard
Our third and last dashboard example shows the answers to a survey on product innovation for a technology company. Just like the previous templates, the interactive and visual nature of the dashboard makes it the perfect tool to interpret data efficiently and effectively.
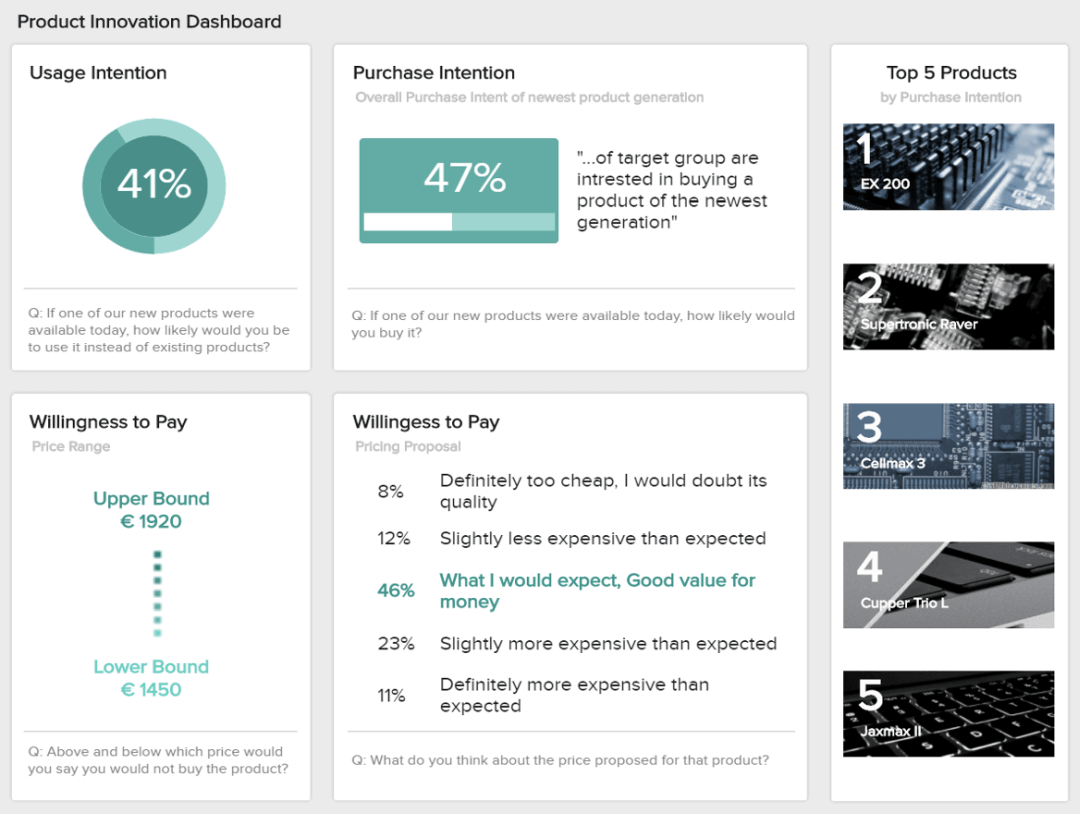
**click to enlarge**
Starting from right to left, we first get a list of the top 5 products by purchase intention. This information lets us understand if the product being evaluated resembles what the audience already intends to purchase. It is a great starting point to see how customers would respond to the new product. This information can be complemented with other key metrics displayed in the dashboard. For example, the usage and purchase intention track how the market would receive the product and if they would purchase it, respectively. Interpreting these values as positive or negative will depend on the company and its expectations regarding the survey.
Complementing these metrics, we have the willingness to pay. Arguably, one of the most important metrics to define pricing strategies. Here, we can see that most respondents think the suggested price is a good value for money. Therefore, we can interpret that the product would sell for that price.
To see more data analysis and interpretation examples for different industries and functions, visit our library of business dashboards.
Use our 14-days free trial & start extracting insights from your data!
To Conclude…
As we reach the end of this insightful post about data interpretation and analysis, we hope you have a clear understanding of the topic. We've covered the definition and given some examples and methods to perform a successful interpretation process.
The importance of data interpretation is undeniable. Dashboards not only bridge the information gap between traditional data interpretation methods and technology, but they can help remedy and prevent the major pitfalls of the process. As a digital age solution, they combine the best of the past and the present to allow for informed decision-making with maximum data interpretation ROI.
To start visualizing your insights in a meaningful and actionable way, test our online reporting software for free with our 14-day trial!