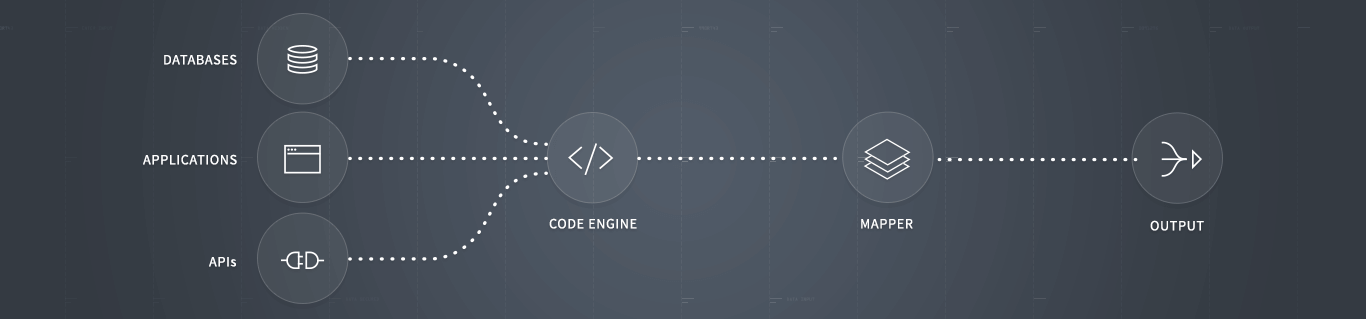
 Any Integration
Any Integration
 End-to-End Security
End-to-End Security
 Managed Schema Changes
Managed Schema Changes
 Mapping Made Easy
Mapping Made Easy
What are ETL Tools & ETL as a service?
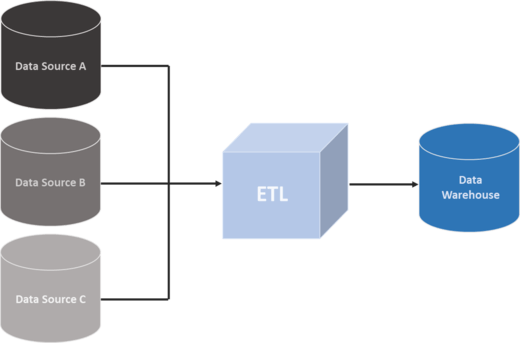
The acronym “ETL” stands for Extract-Transform-Load, the 3 ETL process steps. It is a technology used to read data from a database, transform it into another form thanks to certain processes, and finally load it into another database. It has indeed been extremely useful for many companies, as everywhere in the world we started to accumulate and deal with increasingly big amounts of data. Often enough, all that information was produced and stored on heterogeneous sources, which created the need to transform it in a common format for querying and analysis: ETL tools were created to overcome this issue.
Over the past decade, the number of self-service BI tools grew exponentially, as there was an increasing need for businesses to become more agile and make better informed decisions faster by taking advantage of their data without relying solely on IT teams. But the problem of converting data and setting up complex ETL processes remained – without clean and harmonized information, no analysis is possible. This is why we offer this service along our BI software and relieve you from this pain point that requires time and resources.
Why ETL Tools are important for data integration?
At first, your in-house IT experts may have been able to handle all your data. However, today, the IT is busier than ever as the speed of business has skyrocketed, and they will probably hardly find time to change scripts every time a new data source comes out. The tsunami of data companies are dealing with today is making data migration and integration more complex than ever before. Several converging forces are complexifying data integration, among which the increased use of cloud-based resources, the changing nature of IT itself and the proliferation of devices producing and consuming massive amounts of information at the same time.
When companies are handling big data, they always need analytics available in real or near real-time to make the most accurate data-driven decisions. That means that they can hardly afford to wait for a batch process to run due to an antiquated system, or due to overworked IT teams that cannot focus 100% of their efforts simply on data extraction, transformation and loading. ETL tools are designed as professional grade solutions: they are specifically made to manage and scale up huge amounts of data, without risking errors due to the size of the dataset. They deliver the data in an optimum time, depending on the size and quality of the data source. Achieving the same results, speed and resilience with an internally-made tool needs significant development, a high level of expertise and a quality assurance effort – and all this will cost much more than opting for an ETL tool.
As data integration is an essential part of any BI project, leveraging the capacities of an ETL service will save you time, efforts and money, without compromising the flexibility and scalability required for data integration. ETL tools are thus highly important for the integrity of data that will later be used in decision-making and reporting. This is why we want to help you leverage all the advantages a modern ETL tool brings to your business, by providing you with an ETL as a service offer along our software implementation.
What are the common ETL process steps?
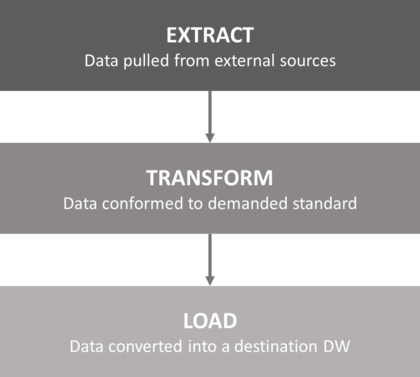
The ETL process includes the three steps that are forming its name: extraction, transformation and loading. The first step is extraction, which means connecting to a data source, and collecting the data needed. The objective of the extraction process is to retrieve this data with as little resources as possible, and it shouldn’t impact negatively the data source in terms of performance, response time or any type of locking.
Secondly, the transformation step executes a set of rules or functions to convert the extracted data to the standard format. It is thus prepared and ‘cleaned’, to be loaded into the end target. This process may be near to real-time, to a couple of hours to several days, depending on the size and the quality of the data source, but also on the business and technical requirements of the target data warehouse or database.
Finally, the loading step will import the extracted and cleaned data into the target database or warehouse. Depending on the requirements, the information can go through an overwriting process to include cumulative information; otherwise, the new data can be added at regular intervals, in an historic form. How often and how much is added or replaced vary according to the resources available, but also depending on the business needs.
Or just leave us a short message. We will come back to you as soon as possible!
Write us now