Misleading Statistics Examples – Discover The Potential For Misuse of Statistics & Data In The Digital Age

Table of Contents
1) What Is A Misleading Statistic?
3) Misleading Statistics Examples In Real Life
Statistical analyses have historically been a stalwart of the high-tech and advanced business industries, and today they are more important than ever. With the rise of advanced technology and globalized operations, statistical analyses grant businesses insight into solving the extreme uncertainties of the market. Studies foster informed decision-making, sound judgments, and actions carried out on the weight of evidence, not assumptions.
As businesses are often forced to follow a difficult-to-interpret market roadmap, statistical methods can help with the planning that is necessary to navigate a landscape filled with potholes, pitfalls, and hostile competition. Statistical studies can also assist in the marketing of goods or services, and in understanding each target market’s unique value drivers. In the digital age, these capabilities are only further enhanced and harnessed through the implementation of advanced technology and business intelligence software. If all this is true, what is the problem with statistics?
Actually, there is no problem per se – but there can be. Statistics are infamous for their ability and potential to exist as misleading and bad data. To get this journey started, let's look at a misleading statistics definition.
What Is A Misleading Statistic?
Misleading statistics refers to the misuse of numerical data either intentionally or by error. The results provide deceiving information that creates false narratives around a topic. Misuse of statistics often happens in advertisements, politics, news, media, and others.
Given the importance of data in today’s rapidly evolving digital world, it is important to be familiar with the basics of misleading statistics and oversight. As an exercise in due diligence, we will review some of the most common forms of misuse of statistics, and various alarming (and sadly, common) misleading statistics examples from public life.
Are Statistics Reliable?
73.6% of statistics are false. Really? No, of course, it’s a made-up number (even though such a study would be interesting to know – but again, could have all the flaws it tries at the same time to point out). Statistical reliability is crucial in order to ensure the precision and validity of the analysis. To make sure the reliability is high, there are various techniques to perform – the first of them being the control tests, which should have similar results when reproducing an experiment in similar conditions. These controlling measures are essential and should be part of any experiment or survey – unfortunately, that isn’t always the case.
While numbers don’t lie, they can in fact be used to mislead with half-truths. This is known as the “misuse of statistics.” It is often assumed that the misuse of statistics is limited to those individuals or companies seeking to gain profit from distorting the truth, be it economics, education, or mass media.
However, the telling of half-truths through study is not only limited to mathematical amateurs. A 2009 investigative survey by Dr. Daniele Fanelli from The University of Edinburgh found that 33.7% of scientists surveyed admitted to questionable research practices, including modifying results to improve outcomes, subjective data interpretation, withholding analytical details, and dropping observations because of gut feelings…. Scientists!
While numbers don’t always have to be fabricated or misleading, it is clear that even society’s most trusted numerical gatekeepers are not immune to the carelessness and bias that can arise with statistical interpretation processes. There are different ways in which statistics can be misleading that we will detail later. The most common one is of course correlation versus causation, which always leaves out another (or two or three) factors that are the actual causation of the problem. Drinking tea increases diabetes by 50%, and baldness raises the cardiovascular disease risk up to 70%! Did we forget to mention the amount of sugar put in the tea or the fact that baldness and old age are related – just like cardiovascular disease risks and old age?
So, can statistics be manipulated? They sure can. Do numbers lie? You can be the judge.
Misleading Statistics Examples In Real Life
Now that we’ve put the misuse of statistics in context, let’s look at various digital age examples of statistics that are misleading across five distinct, but related, spectrums: media and politics, news, advertising, science, and healthcare. While certain topics listed here are likely to stir emotion depending on one’s point of view, their inclusion is for data demonstration purposes only.
1) Examples of misleading statistics in politics
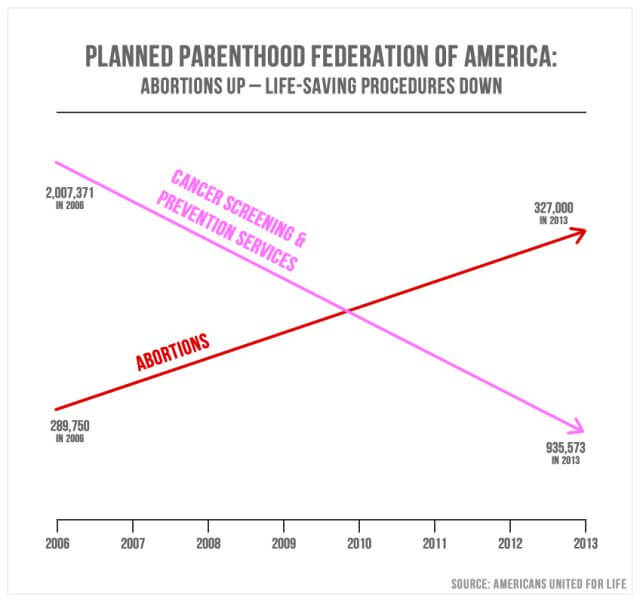
Misleading statistics in politics are quite common. On Sept. 29, 2015, Republicans from the U.S. Congress questioned Cecile Richards, the president of Planned Parenthood, regarding the misappropriation of $500 million in annual federal funding. The above graph/chart was presented as a point of emphasis.
Representative Jason Chaffetz of Utah explained: “In pink, that’s the reduction in the breast exams, and the red is the increase in the abortions. That’s what’s going on in your organization.”
Based on the structure of the chart, it does in fact appear to show that the number of abortions since 2006 experienced substantial growth, while the number of cancer screenings substantially decreased. The intent is to convey a shift in focus from cancer screenings to abortion. The chart points appear to indicate that 327,000 abortions are greater in inherent value than 935,573 cancer screenings. Yet, closer examination will reveal that the chart has no defined y-axis. This means that there is no definable justification for the placement of the visible measurement lines.
Politifact, a fact-checking advocacy website, reviewed Rep. Chaffetz’s numbers via a comparison with Planned Parenthood’s own annual reports. Using a clearly defined scale, here is what the information looks like:

And like this with another valid scale:
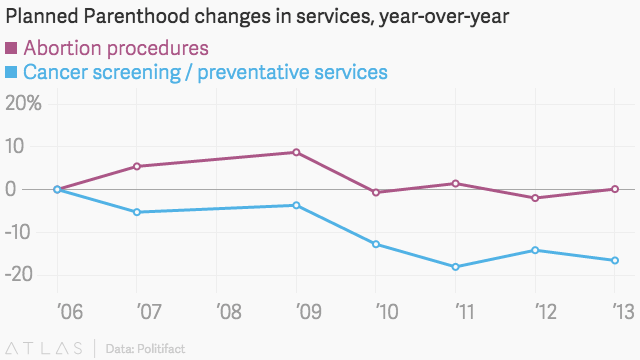
Once placed within a clearly defined scale, it becomes evident that while the amount of cancer screenings has in fact decreased, it still far outnumbers the amount of abortion procedures performed yearly. As such, this is a great misleading statistics example, and some could argue bias considering that the chart originated not from the Congressman, but from Americans United for Life, an anti-abortion group. This is just one of many examples of misleading statistics in the media and politics.
2) Examples of misleading statistics in healthcare
Just like other industries or areas that we will cover on this list of examples, the healthcare industry is not free of the misuse of statistics. Although this controversy happened around 1996, the case of Purdue Pharma and their highly addictive drug OxyContin is still affecting thousands of American citizens and has already taken the lives of thousands of others to this date, all due to the misuse of statistics as a marketing tactic.
The case started when the giant pharmaceutical company, Purdue Pharma, launched its new product OxyContin, which they advertised as a safe, non-addictive opioid that was highly effective for pain relief. Once hearing this statement, doctors were skeptical, as they knew how dangerously addictive opioids could be to treat chronicle pain.
Amongst various videos of “success cases” of patients, merchandising, and unethical messaging included in Purdue’s marketing strategy to advertise OxyContin as a safe drug, there was a very interesting graph, used to prove to doctors that the drug was non-addictive because it stayed on the patient’s blood over time avoiding symptoms of withdrawal. The problem was, the graph, which is depicted below, was built with a y-axis on a logarithmic scale instead of a linear one, making it look like the rate of change is smaller than it actually is.
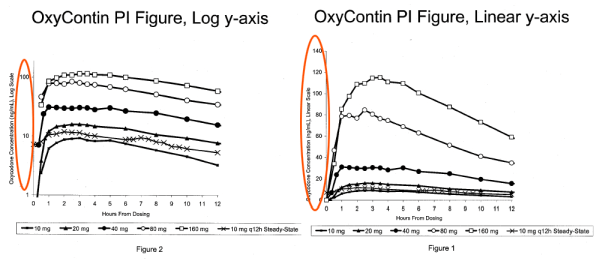
It was this unethical and misleading graph, which was also FDA approved, that helped in initiating one of the biggest health crises in the US, opioid addiction. Although in 2007 the company was forced to pay a $600 million fine for its criminal actions, the consequences of this are still seen to date. This a sad representation of how dangerous misinformation can be.
3) Misleading COVID statistics
This list of misleading statistics fallacy examples would not be complete without referencing the COVID-19 pandemic. During the initial stages of COVID, the general public was forced to consume scientific information in the form of data visualizations to stay informed about the current developments of the virus. But this didn’t come easy. The lack of statistical literacy from the public, paired with the fact that organizations didn’t always share accurate statistical information, lead to widespread misrepresentation of data.
Christopher Engledowl & Travis Weiland wrote an insightful article called “Data (Mis)representation and COVID-19: Leveraging Misleading Data Visualizations For Developing Statistical Literacy Across Grades 6–16”. There, they speak about two use cases in which COVID-19 information was used in a misleading way. Let’s look at one of them closely.
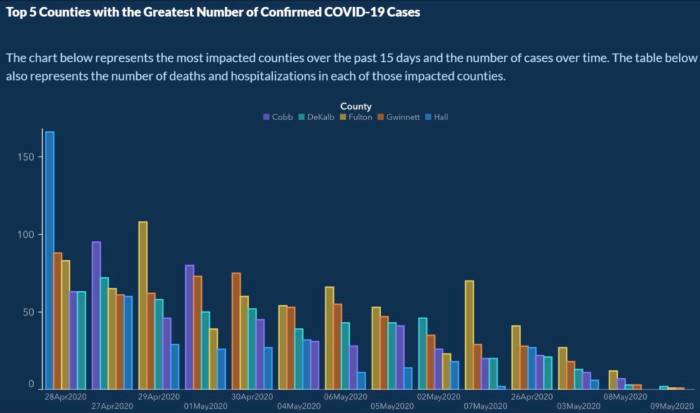
In May 2020, around 5 months after COVID-19 started spreading around the world, the US Georgia Department of Public Health posted a chart that aimed at showing the top 5 counties that had the highest COVID-19 cases in the past 15 days and the number of cases over time.
Source: Vox
Now, if we take a closer look at this chart we can find a few mistakes that make the information very misleading. First of all, the X-axis does not have a label, even though according to the chart, it is meant to show the number of cases over time, this doesn't happen.
Another issue, and maybe the worst of them all, is that the dates under the bars are not ordered chronologically. Instead, we see the dates between April and May interspersed with the aim of making viewers of this graph believe that the cases are gradually decreasing. This is paired with the fact that counties are not always depicted in the same order, but instead in descending order of cases. This is with the same aim of making it seem like the cases are dropping.
The graph generated a big controversy on social media, especially on Twitter, where users pointed out that the Georgia Health Department had repeatedly used misleading statistics during the COVID-19 outbreak. As an answer to the issue, Candice Broce, the communications director for Giorgia’s Governor. Brian Kemp's said: "The x-axis was set up that way to show descending values to more easily demonstrate peak values and counties on those dates, our mission failed. We apologize. It is fixed". The graph was later republished with organized dates and counties. You can see the updated version below.
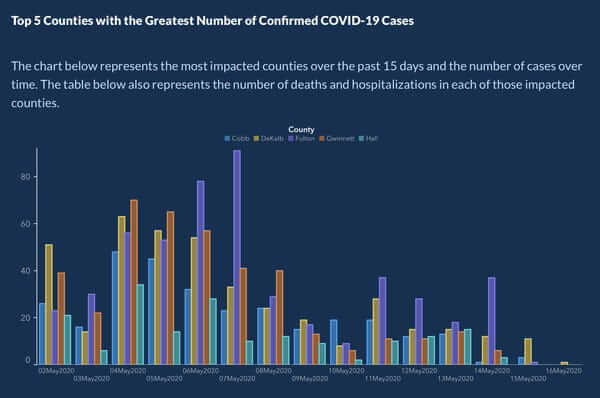
Source: Business Insider
This is one of the many controversial examples of misleading COVID statistics that illustrates the authorities' responsibility to inform their audience accurately. In critical scenarios such as a global pandemic, this becomes even more important as misinformation can lead to a higher spread and more deaths. To avoid situations like this, there is a bunch of healthcare analytics software that assists analysts and average users in the creation of stunning and accurate visualizations for their data.
4) Misleading statistics in advertising

Next, in our list of bad statistics examples, we have the case of a popular toothpaste brand. In 2007, Colgate was ordered by the Advertising Standards Authority (ASA) of the U.K. to abandon their claim: “More than 80% of Dentists recommend Colgate.” The slogan in question was positioned on an advertising billboard in the U.K. and was deemed to be in breach of U.K. advertising rules.
The claim, which was based on surveys of dentists and hygienists carried out by the manufacturer, was found to be misrepresentative as it allowed the participants to select one or more toothpaste brands. The ASA stated that the claim “… would be understood by readers to mean that 80 percent of dentists recommend Colgate over and above other brands, and the remaining 20 percent would recommend different brands.”
The ASA continued, “Because we understood that another competitor’s brand was recommended almost as much as the Colgate brand by the dentists surveyed, we concluded that the claim misleadingly implied 80 percent of dentists recommend Colgate toothpaste in preference to all other brands.” The ASA also claimed that the scripts used for the survey informed the participants that the study was being performed by an independent research company, which was inherently false.
Based on the misuse techniques we covered, it is safe to say that this sleight off-hand technique by Colgate is a clear example of misleading statistics in advertising, and would fall under faulty polling and outright bias.
5) Misleading statistics examples in the news
Misuse of statistics is present everywhere and news outlets are no exception. American network Fox News has been under scrutiny several times throughout the years for showing misleading statistics graphs that seem to purposely portray a conclusion that is not accurate. The most recent case happened not too long ago in September 2021. During one of Fow New’s broadcasts, anchor Tucker Carlson displayed a graph saying that the number of Americans identifying as Christians had collapsed over the last decade.
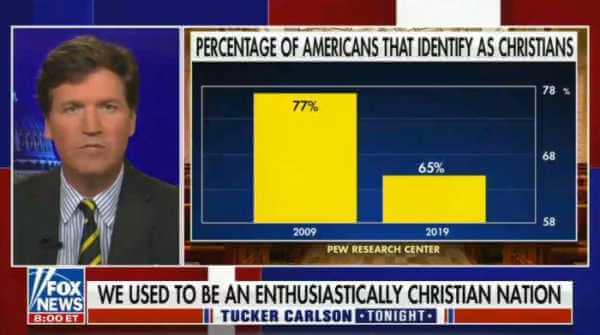
Source: www.rawstory.com
In the image above, we can see a graph showing 77% of Christian Americans in 2009, a number that decreased to 65% in 2019. Now, if the issue here is not obvious enough, we can see that the Y-axis in this chart starts from 58% and ends at 78%, making the 12% drop from 2009 to 2019 look way more significant than it actually is.
As mentioned, this is not the only time Fox News has been criticized because of these situations. Examples of misuse of statistics in the media are very common. Columbia Journalism School professor Bill Grueskin even made a lesson to its students about the topic and used several misleading charts from the US news show as an example of what not to do when presenting data. Grueskin shared some of these insightful examples of misleading statistics in the news in a Twitter thread that became very popular. We took a very obvious one to show you below.
For the presidential run of 2012, the news network showed the graph below where we see a pie chart displaying a total of 193% which is clearly wrong and misleading as the total should be 100%.
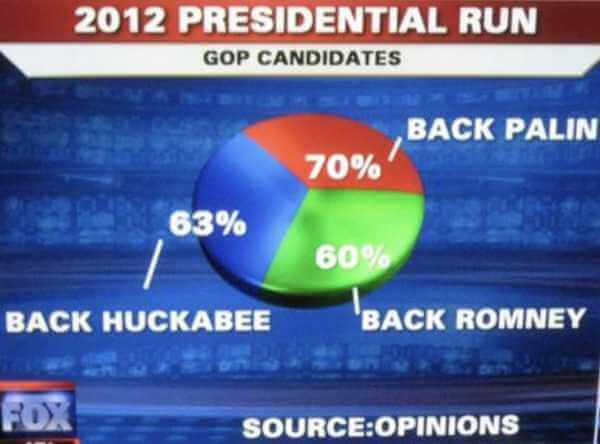
Source: Bill Grueskin
6) Misleading statistics in the media
Television is not the only media platform that can provide examples of bad statistics in the news. In 2006, The Times, a popular UK newspaper, printed a story about how they were the leading paper both online and in print in the UK. The article, titled “The Times leaves the rest behind” started by displaying a graphic of the exponential growth of The Times website visitors from 2004 to 2006. Which saw an increase of millions of visitors in just a couple of years, so far, everything looks normal.
The issue comes with the second graph that is displayed in the article, in which we see a comparison of full-price sales between The Times and one of its biggest competitors, the Daily Telegraph. At a glance, the chart makes you believe that The Times has twice as many full-price subscriptions as its competitor. However, a closer look shows that the X-axis starts at 420,000 instead of 0. Making the difference between the two publications a lot bigger than what it actually is, which is just 10%.
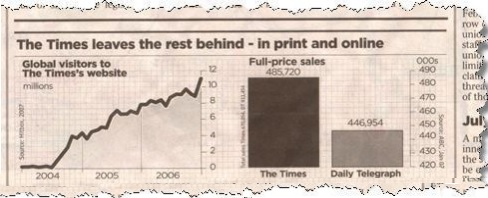
Source: statisticshowto.com
Now, you might argue that The Times is telling the truth, as they are actually leading over their competitors. Regardless, many people will look at the graph and get a different idea of what the actual difference is, which is an unethical and dangerous practice. Just like we saw with Fox News examples, the manipulation of the axes can completely change the way the information on a graph is perceived. We will discuss this specific case in more detail later in the post.
7) Misleading statistics in science
Much like abortion, global warming is another politically charged topic that is likely to arouse emotions. It also happens to be a topic that is vigorously endorsed by both opponents and proponents via studies. Let’s take a look at some of the evidence for and against.
It is generally agreed upon that the global mean temperature in 1998 was 58.3 degrees Fahrenheit. This is according to NASA’s Goddard Institute for Space Studies. In 2012, the global mean temperature was measured at 58.2 degrees. It is, therefore, argued by global warming opponents that, as there was a 0.1-degree decrease in the global mean temperature over a 14-year period, global warming is disproved.
The below graph is the one most often referenced to disprove global warming. It demonstrates the change in air temperature (Celsius) from 1998 to 2012.
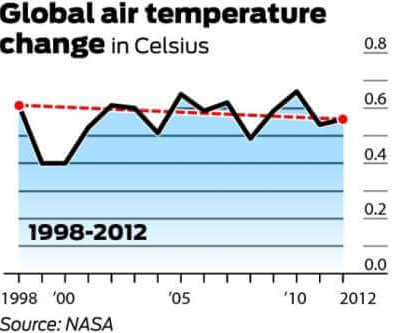
It is worth mentioning that 1998 was one of the hottest years on record due to an abnormally strong El Niño wind current. It is also worth noting that, as there is a large degree of variability within the climate system, temperatures are typically measured with at least a 30-year cycle. The below chart expresses the 30-year change in global mean temperatures.
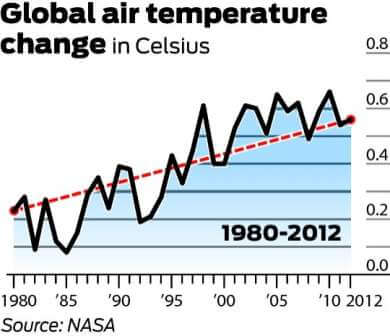
And now have a look at the trend from 1900 to 2012:
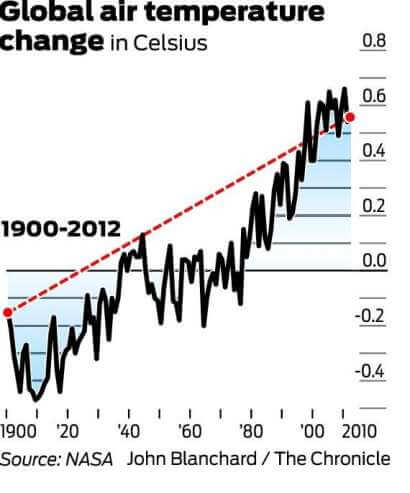
While the long-term data may appear to reflect a plateau, it clearly paints a picture of gradual warming. Therefore, using the first graph, and only the first graph, to disprove global warming is a perfect misleading statistics example.
8) Misleading crime statistics
Rather its politicians trying to make a point for their own interest or just someone not understanding the information behind the graphs and charts they create, crime statistics are not free of being misleading. A controversial representation of this happened in 2014 when a graph depicting the number of murders committed using firearms in Florida from 1990 to 2010 was published in the context of the “Stand Your Ground” law, enacted in 2005 to give people the right to use deadly force for self-defense.
At a first glance, the graph, which is displayed below, shows a descending trend that starts the year the law was enacted, concluding that “Stand Your Grown” is responsible for the apparent drop in the number of murders committed using firearms in the years after it was implemented. However, when taking a closer look at the graph, we can see that the y-axis is reversed, starting with the highest numbers at the bottom and reaching 0 at the top.
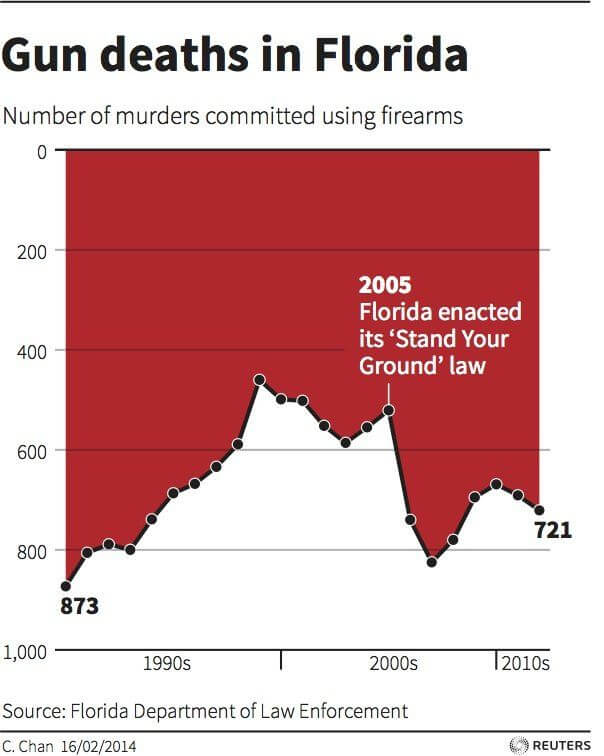
Source: livescience.com
Taking that into account, what the graph is actually showing is an increase in deaths using firearms after the law was enacted. Now, as we learned throughout this post, we can’t say with certainty that the law caused the rise in deaths as there are other factors that could influence that number. There is also no evidence to say that the Florida Law Enforcement Department was purposely deceiving the public. However, at the time this graph was published, many media publications interpreted the graph as if the deaths dropped, showing how damaging the misuse of graphs and numbers can be.
Explore our 14-days free trial & ensure data integrity across the board!
How Can Statistics Be Misleading

Remember, misuse of statistics can be accidental or purposeful. While a malicious intent to blur lines with misleading statistics will surely magnify bias, the intent is not necessary to create misunderstandings. The misuse of statistics is a much broader problem that now permeates multiple industries and fields of study. Here are a few potential mishaps that commonly lead to misuse:
1) Faulty polling
The manner in which questions are phrased can have a huge impact on the way an audience answers them. Specific wording patterns have a persuasive effect and induce respondents to answer in a predictable manner. For example, on a poll seeking tax opinions, let’s look at the two potential questions:
- Do you believe that you should be taxed so other citizens don’t have to work?
- Do you think that the government should help those people who cannot find work?
These two questions are likely to provoke far different responses, even though they deal with the same topic of government assistance. These are examples of “loaded questions.”
A more accurate way of wording the question would be, “Do you support government assistance programs for unemployment?” or, (even more neutrally) “What is your point of view regarding unemployment assistance?”
The latter two examples of the original questions eliminate any inference or suggestion from the poller, and thus, are significantly more impartial. Another unfair method of polling is to ask a question, but precede it with a conditional statement or a statement of fact. Staying with our example, that would look like this: “Given the rising costs to the middle class, do you support government assistance programs?”
A good rule of thumb is to always take polling with a grain of salt and to try to review the questions that were actually presented. They provide great insight, often more so than the answers.
2) Flawed correlations
The problem with correlations is this: if you measure enough variables, eventually it will appear that some of them correlate. As one out of twenty will inevitably be deemed significant without any direct correlation, studies can be manipulated (with enough data) to prove a correlation that does not exist or that is not significant enough to prove causation.
To illustrate this point further, let’s assume that a study has found a correlation between an increase in car accidents in the state of New York in the month of June (A), and an increase in bear attacks in the state of New York in the month of June (B).
That means there will likely be six possible explanations:
- Car accidents (A) cause bear attacks (B)
- Bear attacks (B) cause car accidents (A)
- Car accidents (A) and bear attacks (B) partly cause each other
- Car accidents (A) and bear attacks (B) are caused by a third factor (C)
- Bear attacks (B) are caused by a third factor (C) which correlates to car accidents (A)
- The correlation is only chance
Any sensible person would easily identify the fact that car accidents do not cause bear attacks. Each is likely a result of a third factor, that being: an increased population, due to the high tourism season in the month of June. It would be preposterous to say that they cause each other... and that is exactly why it is our example. It is easy to see a correlation.
But, what about causation? What if the measured variables were different? What if it was something more believable, like Alzheimer’s and old age? Clearly, there is a correlation between the two, but is there causation? Many would falsely assume, yes, solely based on the strength of the correlation. Tread carefully, for either knowingly or ignorantly, correlation hunting will continue to exist within statistical studies.
3) Data fishing
This misleading data example is also referred to as “data dredging” (and related to flawed correlations). It is a data mining technique where extremely large volumes of data are analyzed for the purpose of discovering relationships between different points. Seeking a relationship between data isn’t a misuse per se, however, doing so without a hypothesis is.
Data dredging is a self-serving technique often employed for the unethical purpose of circumventing traditional data mining techniques, in order to seek additional conclusions that do not exist. This is not to say that there is no proper use of data mining, as it can in fact lead to surprise outliers and interesting analyses. However, more often than not, data dredging is used to assume the existence of relationships without further study.
Oftentimes, data fishing results in studies that are highly publicized due to their important or outlandish findings. These studies are very soon contradicted by other important or outlandish findings. These false correlations often leave the general public very confused and searching for answers regarding the significance of causation and correlation.
Likewise, another common practice with data is omission, meaning that after looking at a large data set of answers, you only pick the ones that are supporting your views and findings and leave out those that contradict them. As mentioned at the beginning of this article, it has been shown that a third of the scientists admitted that they had questionable research practices, including withholding analytical details and modifying results...! But then again, we are facing a study that could itself fall into this 33% of questionable practices, faulty polling, and selective bias... It becomes hard to believe any analysis!
4) Misleading data visualization
Insightful graphs and charts include a very basic, but essential, grouping of elements. Whatever the types of graphs and charts you choose to use, it must convey:
- The scales used
- The starting value (zero or otherwise)
- The method of calculation (e.g., dataset and time period)
Absent these elements, visual data representations should be viewed with a grain of salt, taking into account the common data visualization mistakes one can make. Intermediate data points should also be identified and context is given if it would add value to the information presented. With the increasing reliance on intelligent solution automation for variable data point comparisons, best practices (i.e., design and scaling) should be implemented prior to comparing data from different sources, datasets, times, and locations.
5) Purposeful and selective bias
The next of our most common examples for misuse of statistics and misleading data is, perhaps, the most serious. Purposeful bias is the deliberate attempt to influence findings without even feigning professional accountability. Bias is most likely to take the form of data omissions or adjustments to prove a specific point.
The selective bias is slightly more discreet for those who do not read the small lines. It usually falls down on the sample of people surveyed. For instance, the nature of the group of people surveyed: asking a class of college students about the legal drinking age, or a group of retired people about the elderly care system. You will end up with a statistical error called “selective bias”. To avoid this issue, you should always pick a random sample of people whose background may or may not be related to the topic of the survey.
Businesses and analysts are exposed to making biases when a single person is doing an entire analysis. Whether this person notices or not, they might be providing an inaccurate or manipulated picture to confirm a specific conclusion. This can lead to poor decision-making due to misinformation.
6) Percentage change in combination with a small sample size
Another way of creating misleading statistics, also linked with the choice of sample discussed above, is the size of said sample. When an experiment or a survey is led on a totally not significant sample size, not only will the results be unusable, but the way of presenting them - namely as percentages - will be totally misleading.
Asking a question to a sample size of 20 people, where 19 answers "yes" (=95% say for yes) versus asking the same question to 1,000 people and 950 answers "yes" (=95% as well): the validity of the percentage is clearly not the same. Providing solely the percentage of change without the total numbers or sample size will be totally misleading. xkdc's comic illustrates this very well, to show how the "fastest-growing" claim is a totally relative marketing speech:

Likewise, the needed sample size is influenced by the kind of question you ask, the statistical significance you need (clinical study vs business study), and the statistical technique. If you perform a quantitative analysis, sample sizes under 200 people are usually invalid.
7) Truncating an axis
Truncating an axis is another way in which statistics can be misleading. When creating a graph to portray a statistic, it is natural to assume that the X and Y axes start at zero. Truncating axes means doing the opposite. For example, starting the axes in a predefined value so that it will affect the way the graph is perceived to achieve a certain conclusion. This technique is often used in politics to exaggerate a result that would otherwise be much less interesting.
Let’s put this into perspective with an example of the misuse of statistics in advertising. The image below shows a graph advertising KFC’s crispy chicken twister wrap and comparing its calories with other brands with a similar product. As we can see, the X axes here start from 590 instead of zero. This makes it appear that KFC’s wrap has half the calories as the ones from Taco Bell, Burger King, or Wendy’s when is actually just 70 calories less.

Source: Reddit “Data Is Ugly”
This is a clear situation in which the axes are manipulated to show a specific result that is misleading. Truncating axes is a very dangerous false statistics practice, as it can help create wrong narratives around important topics. In this case, it can create the wrong idea of a product being healthier than it actually is.
8) Strategically picking the time period
Another common misuse of statistics is strategically picking the time period to show a result. This is a case of misleading statistics that can be done purposely, to achieve a specific result, or accidentally. For example, picking only a good-performing month to build a sales report will portray a misleading picture of the overall sales performance.
Purposely or not, the time periods we choose to portray will affect the way viewers perceive the data. For instance, showing a value for 3 months can show radically different trends than showing it over a year. The image below is a great example of this misleading practice. You can see a graph that shows the UK National debt from 1995 to 2016. If you see this graph, you would obviously think the UK’s national debt is higher than ever.
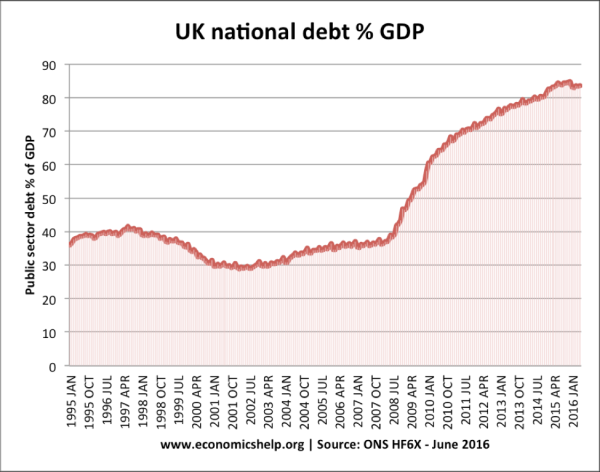
Source: www.economicshelp.org
However, when you look at a longer time period such as 1910 to 2015 (image below) we realize that the debt is actually very low comparing it to other years. Making this a clear example of how the time period that we chose to portray can significantly change the way people will perceive the information.
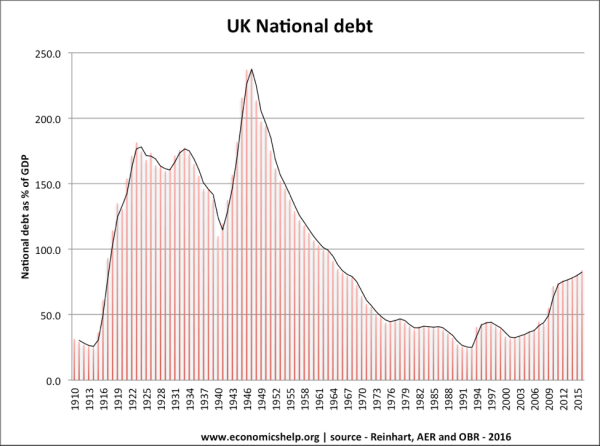
Source: www.economicshelp.org
9) Simpson’s Paradox
According to a definition by the Stanford Encyclopedia of Philosophy, a Simpson’s Paradox is a statistical phenomenon where “an association between two variables in a population emerges, disappears or reverses when the population is divided into subpopulations”. Now, you might be wondering, how can this be misleading?
Well, a Simpson’s Paradox can happen when an analyst doesn’t look at the complete scope of the data. When this paradox goes unnoticed, it can significantly influence the way the data is interpreted, leaving room to believe a certain conclusion or assumption is an absolute truth, when it could change by looking at it from a different perspective.
Let’s explain this better with an example. Imagine you are in need of risky emergency surgery and have to choose between going to hospitals A or B to get it. Doing a quick research, you find that 900 out of 1000 patients that went into surgery at Hospital A survived, while 800 out of 1000 survived at Hospital B. Now, the obvious answer is going for option A. However, when considering other factors such as the health conditions in which patients arrived at the hospitals we can drive other conclusions. For instance, of 100 patients that arrived in poor condition in Hospital A, 30 survived. On the other side, of 400 patients that arrived in poor condition at Hospital B, 210 survived at a survival rate of 52.5%.
While initially, the trend was going towards choosing option A, when grouping surviving patients considering other variables the trend changed to option B. This is a Simpson’s Paradox at its finest, and it happens when the data hides a conditional variable that can significantly influence the results.
How To Avoid & Identify The Misuse Of Statistics?
Now that we’ve looked at examples and common cases of misuse of statistics, you might be wondering, how do I avoid all of this? A first good thing would be, of course, to stand in front of an honest survey/experiment/research – pick the one you have beneath your eyes –, that has applied the correct techniques of collection and interpretation of data. But you cannot know until you ask yourself a couple of questions and analyze the results you have in between your hands.
Who is doing the research?
As an entrepreneur and former consultant, Mark Suster advises in an article, you should wonder who did the primary research of said analysis. Independent university study group, lab-affiliated research team, consulting company? From there naturally stems the question: who paid them? As no one works for free, it is always interesting to know who sponsors the research. Likewise, what are the motives behind it? What did the scientist or statisticians try to figure out? Finally, how big was the sample set, and who was part of it? How inclusive was it?
These are important questions to ponder and answer before spreading everywhere skewed or biased results – even though it happens all the time, because of amplification. A typical example of amplification often happens with newspapers and journalists, who take one piece of data and need to turn it into headlines – thus often out of its original context. No one buys a magazine where it states that next year, the same thing is going to happen in XYZ market as this year – even though it is true. Editors, clients, and people want something new, not something they know; that’s why we often end up with an amplification phenomenon that gets echoed and more than it should.
Is the sample size big enough?
As we mentioned earlier, the sample size is of utmost importance when it comes to deciding the worth of a study or its results. If the sample size of the study is too small to prove its conclusion then you should be responsible enough and not use these results as an absolute truth as this paves the way for future misinformation. If you still want to use the data to make a point, you can make sure to mention the small sample size as a disclaimer. That said, a bigger sample size is always better, as it highlights statistical differences more accurately.
Is the language being used objective and formal?
The power of words is huge, therefore, carefully looking at the way a study is written is another great practice to assess its quality. No matter how good a study might be, if it's not written using objective and formal language, then it is at risk to mislead. Researchers should not allow their values, their bias, or their views to impact their research, analysis, or findings, therefore, looking at the way questions and findings are formulated is a good practice.
Are the visuals being used correctly?
If you are the one performing the analysis, for instance generating reports for your job, you can ask yourself a few relevant questions to avoid using misleading statistics. For example, are visualizations representing the data accurately? (labels are clear, axes begin at 0, right chart type, etc) Is the research represented honestly and in an impartial manner? What information is missing from this data? You can also ask someone external to your research to look at the data, someone biased to the topic that can confirm your results are not misleading.
As you saw throughout this post, illustrated with some insightful bad statistics examples, using data in a misleading way is very easy. If you follow all the steps mentioned above, you should be able to make a clear analysis and correct use of data.
Explore our 14-days free trial & ensure data integrity across the board!
Misuse of Statistics - A Summary
To the question "can statistics be manipulated?", we can address 8 methods often used - on purpose or not - that skew the analysis and the results. Here are common types of misuse of statistics:
- Faulty polling
- Flawed correlations
- Data fishing
- Misleading data visualization
- Purposeful and selective bias
- Using percentage change in combination with a small sample size
- Truncating an axis
- Strategically picking the time period
Now that you know them, it will be easier to spot them and question all the stats that are given to you every day. Likewise, in order to ensure you keep a certain distance to the studies and surveys you read, remember the questions to ask yourself - who researched and why, who paid for it, and what was the sample.
Transparency and Data-Driven Business Solutions
While it is quite clear that statistical data has the potential to be misused, it can also ethically drive market value in the digital world. Big data has the ability to provide digital age businesses with a roadmap for efficiency and transparency, and eventually, profitability. Advanced technology solutions like online reporting software can enhance statistical data models, and provide digital age businesses with a step up on their competition.
Whether for market intelligence, customer experience, or business reporting, the future of data is now. Take care to apply data responsibly, ethically, and visually, and watch your transparent corporate identity grow. Revisit this insightful list of bad statistics examples from time to time to remind you of the importance of using data in a proper way!