The Ultimate Guide to Modern Data Quality Management (DQM) For An Effective Data Quality Control Driven by The Right Metrics

Table of Contents
1) What Is Data Quality Management?
4) Data Quality Best Practices
5) How Do You Measure Data Quality?
6) Data Quality Metrics Examples
7) Data Quality Control: Use Case
8) The Consequences Of Bad Data Quality
9) 3 Sources Of Low-Quality Data
With a shocking 2.5 quintillion bytes of data being produced daily and the wide range of online data analysis tools in the market, the use of data and analytics has never been more accessible.
However, with all good things comes many challenges, and businesses often struggle with correctly managing their information. Oftentimes, the data being collected and used is incomplete or damaged, leading to many other issues that can considerably harm the company. Enters data quality management.
What Is Data Quality Management (DQM)?
Data quality management is a set of practices that aim at maintaining a high quality of information. It goes all the way from the acquisition of data and the implementation of advanced data processes to an effective distribution of data. It also requires a managerial oversight of the information you have. Effective DQM is recognized as essential to any consistent data analysis, as data quality is crucial to derive actionable and - more importantly - accurate insights from your information.
There are a lot of strategies that you can use to improve the quality of your information. Engineered to be the “Swiss Army Knife” of data development, these processes prepare your organization to face the challenges of digital age data, wherever and whenever they appear. In this article, we will detail everything that is at stake when we talk about data quality management: why it is essential, how to measure data quality, the pillars of good quality management, and some data quality control techniques. Reporting being part of an effective data quality management model, we will also go through some KPI examples you can use to assess your efforts in the matter. But first, let’s define what it actually is.
What is the definition of data quality?
Data quality refers to the assessment of the information you have relative to its purpose and its ability to serve that purpose. The quality of data is defined by different factors that will be detailed later in this article, such as accuracy, completeness, consistency, or timeliness. That quality is necessary to fulfill the needs of an organization in terms of operations, planning, and decision-making.
What is the data quality management lifecycle?
Big data and analytics have become one of the biggest competitive advantages that organizations have today. That being said, while the process of analyzing data has become easier with the use of self service SaaS BI tools, managing data quality still remains one of the biggest challenges for companies of all sizes. But don’t worry; if you are reading this article, you are already on the right path to extract the maximum potential out of your data-driven efforts. Implementing an efficient framework to clean and manage your information is the first step to getting started. We will dive into detail into each step of the data quality process later in the post, but below, we will discuss them briefly to help you understand what you should expect from the process.
- Extraction: Gathering the necessary information from various internal and external sources.
- Evaluate: Evaluate if the data you gathered meets the quality requirements.
- Cleansing: Clean, remove, or delete any information that is duplicated, wrongly formatted, or useless for your goals.
- Integration: Integrate your data sources to get a complete view of your information.
- Reporting: Use KPIs to monitor the quality of your data and ensure no further issues happen.
- Repair: If your reports show data that is corrupt or needs something changed, fix it promptly.
Why Do You Need Data Quality Management?
While the digital age has been successful in prompting innovation far and wide, it has also facilitated what is referred to as the “data crisis” - low-quality data.
Today, most of a company's operations and strategic decisions heavily rely on data, so the importance of quality is even higher. Indeed, low-quality data is the leading cause of failure for advanced data and technology initiatives, to the tune of $9.7 million to American businesses each year (not counting businesses in every other country of the world). More generally, low-quality data can impact productivity, bottom line, and overall ROI.
We’ll get into some of the consequences of poor-quality data in a moment. However, let’s make sure not to get caught in the “quality trap,” because the ultimate goal of DQM is not to create subjective notions of what “high-quality” data is. No, its ultimate goal is to increase return on investment (ROI) for those business segments that depend upon data. Paired with this, it can also:
Improved decision-making process: From customer relationship management to supply chain management to enterprise resource planning, the benefits of data quality management can have a ripple impact on an organization’s performance. With quality data at their disposal, organizations can form data warehouses to examine trends and establish future-facing strategies. Industry-wide, the positive ROI on quality data is well understood. According to a big data survey by Accenture, 92% of executives using big data to manage are satisfied with the results, and 89% rate data as “very” or “extremely” important, as it will “revolutionize operations the same way the internet did”.
Save time and money: As you will see throughout this insightful post, the consequences of using bad quality data to make important business decisions can not only lead to a waste of time in inefficient strategies but to an even higher loss in money and resources. Taking that into account, it is of uppermost importance for companies to invest in the right processes, systems, and tools to make sure the quality of their data is meeting the needed standards. As a result, not only will the business save tons of money and resources, but will also reap the rewards of making informed decisions based on accurate insights.
Competitive advantage: As mentioned in the previous points, the bottom line of being in possession of good quality data is improved performance across all areas of the organization. From customer relations to marketing, sales, and finances, being able to make informed decisions with your own data is invaluable in today’s fast-paced world. Getting a clear picture of what steps you should follow to be successful will lead to gaining a clear competitive advantage that will set the organization apart from the rest.
Now that you have a clearer understanding of the benefits you can reap from implementing this process in your organization, let’s explore the concept in more detail.
The 5 Pillars of Data Quality Management
Now that you understand the importance of high-quality data and want to take action to solidify your data foundation let’s take a look at the techniques behind DQM and the 5 pillars supporting it.
1 – The people
Technology is only as efficient as the individuals who implement it. We may function within a technologically advanced business society, but human oversight and process implementation have not (yet) been rendered obsolete. Therefore, several roles need to be filled, including:
DQM Program Manager: The program manager role should be filled by a high-level leader who accepts the responsibility of general oversight for business intelligence initiatives. He/she should also oversee the management of the daily activities involving data scope, project budget, and program implementation. The program manager should lead the vision for quality data and ROI.
Organization Change Manager: The change manager does exactly what the title suggests: organizing. He/she assists the organization by providing clarity and insight into advanced data technology solutions. As quality issues are often highlighted with the use of dashboard software, the change manager plays an important role in the visualization of data quality.
Business/Data Analyst: The business analyst is all about the “meat and potatoes” of the business. This individual defines the quality needs from an organizational perspective. These needs are then quantified into data models for acquisition and delivery. This person (or group of individuals) ensures that the theory behind data quality is communicated to the development team.
2 – Data profiling
Data profiling is an essential process in the DQM lifecycle. It involves:
- Reviewing data in detail
- Comparing and contrasting the data to its own metadata
- Running statistical models
- Data quality reports
This process is initiated for the purpose of developing insight into existing data, with the purpose of comparing it to quality goals. It helps businesses develop a starting point in the DQM process and sets the standard for how to improve their information quality. The data quality analysis metrics of complete and accurate data are imperative to this step. Accurate data is looking for disproportionate numbers, and complete data is defining the data body and ensuring that all data points are whole. We will go over them in the third part of this article.
3 – Defining data quality
The third pillar is quality itself. “Quality rules” should be created and defined based on business goals and requirements. These are the business/technical rules with which data must comply in order to be considered viable.
Business requirements are likely to take a front seat in this pillar, as critical data elements should depend upon the industry. The development of quality rules is essential to the success of any DQM process, as the rules will detect and prevent compromised data from infecting the health of the whole set.
Much like antibodies detecting and correcting viruses within our bodies, data quality rules will correct inconsistencies among valuable data. When teamed together with online BI tools, these rules can be key in predicting trends and reporting analytics.
4 – Data reporting
Data quality reporting is the process of removing and recording all compromising data. This should be designed to follow a natural process of data rule enforcement. Once exceptions have been identified and captured, they should be aggregated so that quality patterns can be identified.
The captured data points should be modeled and defined based on specific characteristics (e.g., by rule, by date, by source, etc.). Once this data is tallied, it can be connected to an online reporting software to report on the state of quality and the exceptions that exist within a data quality dashboard. If possible, automated reporting and “on-demand” technology solutions should be implemented as well, so dashboard insights can appear in real-time.
Reporting and monitoring are the cruces of enterprise data quality management ROI, as they provide visibility into the state of data at any moment in real-time. By allowing businesses to identify the location and domiciles of data exceptions, teams of data specialists can begin to strategize remediation processes.
Knowledge of where to begin engaging in proactive data adjustments will help businesses move a step closer to recovering their part of the $9.7 billion lost each year to low-quality data.
5 – Data repair
Data repair is the two-step process of determining:
- The best way to remediate data
- The most efficient manner in which to implement the change
The most important aspect of data remediation is the performance of a “root cause” examination to determine why, where, and how the data defect originated. Once this examination has been implemented, the remediation plan should begin.
Data processes that depended upon the previously defective data will likely need to be re-initiated, especially if their functioning was at risk or compromised by the defective data. These processes could include reports, campaigns, or financial documentation.
This is also the point where data quality rules should be reviewed again. The review process will help determine if the rules need to be adjusted or updated, and it will help begin the process of data evolution. Once data is deemed high-quality, critical business processes and functions should run more efficiently and accurately, with a higher ROI and lower costs.
Data Quality Management Best Practices

Through the 5 pillars that we just presented above, we also covered some techniques and tips that should be followed to ensure a successful process. To help you digest all that information, we put together a brief summary of all the points you should not forget when it comes to assessing your data. By following these best practices, you should be able to leave your information ready to be analyzed.
- Ensure data governance: Data governance is a set of processes, roles, standards, and KPIs that ensure organizations use data efficiently and securely. Implementing a governance system is a fundamental step to ensuring data quality management roles and responsibilities are defined. It is also fundamental to keep every employee accountable for how they access and manipulate data.
- Involve all departments: As we mentioned before, there are roles and responsibilities that are required when it comes to dealing with data quality. Some of these roles include a data quality manager, data analyst, and more. That said, while the need for specialized people is a must, it is also necessary to involve the entire organization in the process.
- Ensure transparency: Expanding on the previous point, to successfully integrate every relevant stakeholder in the process, it is necessary to offer a high level of transparency to them. Ensure all the rules and processes regarding data management are informed across the organization to avoid any mistakes from damaging your efforts.
- Define a data glossary: As a part of your governance plan, a good practice is to produce a data glossary. This should contain a collection of all relevant terms that are used to define the company data in a way that is accessible and easy to navigate. This way, you make sure there is a common understanding of data definitions that are being used across the organization.
- Find the root causes for quality issues: If you find poor data quality issues in your business, it is not necessary to just toss it all out. Bad-quality data can also provide insights that will help you improve your processes in the future. A good practice here is to review the current data, find the root of the quality issues, and fix them. This will not only help you set the grounds to work with clean, high-quality data but will also help you identify common issues that can be avoided or prevented in the future.
- Invest in automation: Manual data entry is considered among the most common causes of poor data quality due to the high possibility of human error. This threat becomes even bigger in companies that require many people to do data entry. To avoid this from happening, it is a good practice to invest in automation tools to take care of the entry process. These tools can be configured to your rules and integrations and can ensure your data is accurate across the board.
- Implement security processes: During your quality control process, you must archive, cleanse, recover, and delete data from many sources. This data might also need to be accessed by a number of people. Therefore, you need to ensure efficient security measures are in place to prevent any breaches or misuse of data. To do so, you can support yourself with modern management tools that offer top-notch security features.
- Define KPIs: Just like any other analytical process, DQM requires the use of KPIs to assess the success and performance of your efforts. In this case, it is important to define quality KPIs that are also related to your general business goals. This step is a detrimental part of the process, and we will cover it in detail in the next portion of the post.
- Integrate DQM and BI: Integration is one of the buzzwords when we talk about data analysis in a business context. Implementing DQM processes allows companies across industries to perform improved business intelligence. That said, integrating data quality management processes with BI software can help automate the task and ensure better strategic decisions across the board.
- Measure compliance: Last but not least, once you’ve implemented your DQM framework, you need to measure compliance in two key areas. First, you need to evaluate if the policies and standards applied in the previous points are being followed from an internal perspective. Then, you need to evaluate if, overall, the company is meeting the regulatory standards for data usage.
How Do You Measure Data Quality?
To measure data quality, you obviously need data quality metrics. They are also key in assessing your efforts to increase the quality of your information. Among the various techniques, data quality metrics must be top-notch and clearly defined. These indicators encompass different aspects of quality that can be summed up with the acronym "ACCIT" standing for Accuracy, Consistency, Completeness, Integrity, and Timeliness.
While data analysis can be quite complex, there are a few basic measurements that all key DQM stakeholders should be aware of. Data quality metrics are essential to provide the best and most solid basis you can have for future analyses. These indicators can be visualized together in an interactive report with the help of professional BI reporting tools which will also help you track the effectiveness of your quality improvement efforts, which is, of course, needed to make sure you are on the right track. Let's go over these categories and detail what they hold.
Accuracy
Refers to business transactions or status changes as they happen in real time. Accuracy should be measured through source documentation (i.e., from the business interactions), but if not available, then through confirmation techniques of an independent nature. It will indicate whether the data is void of significant errors.
A typical metric to measure accuracy is the ratio of data to errors, which tracks the number of known errors (like missing, incomplete, or redundant entries) relative to the data set. This ratio should, of course, increase over time, proving that the quality of your data gets better. There is no specific ratio of data to errors, as it very much depends on the size and nature of your data set - but the higher, the better of course. In the example below, we see that the data-to-error rate is just below the target of 95% accuracy:
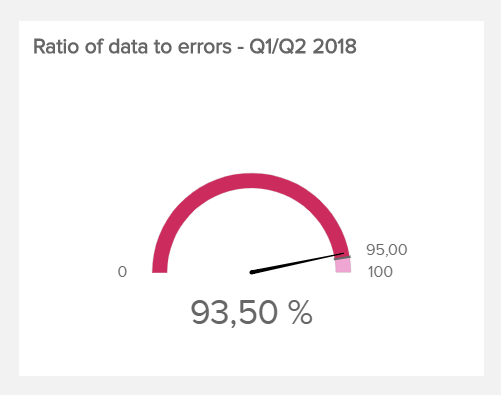
Consistency
Strictly speaking, consistency specifies that two data values pulled from separate data sets should not conflict with each other. However, consistency does not automatically imply correctness.
An example of consistency is, for instance, a rule verifying that the sum of employees in each company's department does not exceed the total number of employees in that organization.
Completeness
Completeness will indicate if there is enough information to draw conclusions. Completeness can be measured by determining whether or not each data entry is a “full” data entry. All available data entry fields must be complete, and sets of data records should not be missing any pertinent information.
For instance, a simple quality metric you can use is the number of empty values within a data set. In an inventory/warehousing context, that means that each line of an item refers to a product, and each of them must have a product identifier. Until that product identifier is filled, the line item is not valid. You should then monitor that metric for a longer period to reduce it.
Integrity
Also known as data validation, integrity refers to the structural testing of data to ensure that the data complies with procedures. This means there are no unintended data errors, and it corresponds to its appropriate designation (e.g., date, month, and year).
Here, it all comes down to the data transformation error rate. The metric you want to use tracks how many data transformation operations fail relatively to the whole - or in other words, how often the process of taking data stored in one format and converting it to a different one is not successfully performed. In our example below, the transformation error rate is represented over time:
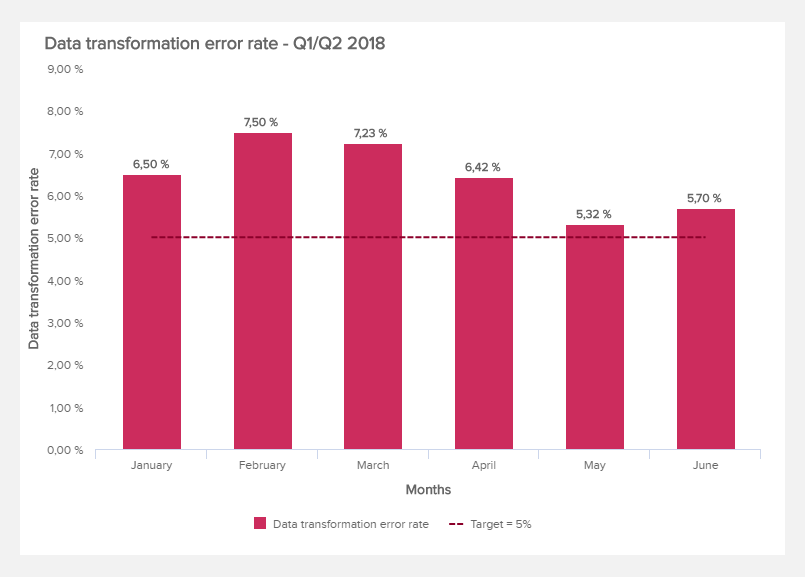
Timeliness
Timeliness corresponds to the expectation for the availability and accessibility of information. In other words, it measures the time between when data is expected and the moment when it is readily available for use.
A metric to evaluate timeliness is the data time-to-value. This is essential to measure and optimize this time, as it has many repercussions on the success of a business. The best moment to derive valuable information of data is always now, so the earliest you have access to that information, the better.
Whichever way you choose to improve the quality of your data, you will always need to measure the effectiveness of your efforts. All of these data quality metrics examples make a good assessment of your processes and shouldn't be left out of the picture. The more you assess, the better you can improve.
Uniqueness
As its name suggests, the next quality dimension helps to determine if a specific value or dataset is recorded twice with the same identifier. It helps avoid duplications or overlaps, as having two or multiple copies of the same value can cause problems during the analysis as some of the copies might not be updated or correctly formatted or might be considered a different value altogether. Uniqueness is often used together with consistency as both help ensure the is unique and correct across sources.
For example, imagine your company has 100 full-time employees and 80 part-time ones with a total of 180 contracted employees. However, your employee database shows a total of 220 employees. This could mean that an employee called Thomas Smith can be recorded separately as Tom Smith despite being the same person. This means your uniqueness rate would not be 100%. Cleaning the data to erase duplicates is the best way to ensure a high uniqueness score.
Validity
This dimension helps evaluate if the data is valid according to its format, database types, and overall definition. For instance, ZIP codes are valid if they have the correct format for a specific region, dates need to be set in the correct order and format, and so on. Failing to do so can lead your database to classify the value as invalid and affect the accuracy and completeness of your data.
To ensure data validity, you can set rules to tell your system to ignore or resolve the invalid value and ensure completeness. For example, imagine you are generating a database to classify customers with the identifier of name and surname. So, if a customer is called Marie Cooper, the data is valid, and it should be no problem to integrate. Now, if a customer is called Jean Paul Ross. The database might consider it invalid as the accepted format is name and surname. To avoid this, you can set a rule to ensure that customers with up to two names are also considered valid.
What Are Data Quality Metrics Examples?

Find here 5 data quality metrics examples you can use:
- The ratio of data to errors: Monitors the number of known data errors compared to the entire data set.
- A number of empty values: Counts the times you have an empty field within a data set.
- Data time-to-value: evaluates how long it takes you to gain insights from a data set. There are other factors influencing it, yet the quality is one of the main reasons it can increase.
- Data transformation error rate: This metric tracks how often a data transformation operation fails.
- Data storage costs: When your storage costs go up while the amount of data you use remains the same, or worse, decreases, it might mean that a significant part of the data stored has a quality too low to be used.
Why You Need Data Quality Control: Use Case
Let’s examine the benefits of high-quality data in marketing. Imagine you have a list you purchased with 10,000 emails, names, phone numbers, businesses, and addresses on it. Then, imagine that 20% of that list is inaccurate. That means that 20% of your list has either the wrong email, name, phone number, etc. How does that translate into numbers?
Well, look at it like this: if you run a Facebook ad campaign targeting the names on this list, the cost will be up to 20% higher than it should be - because of those false name entries. If you do physical mail, up to 20% of your letters won’t even reach their recipients. With phone calls, your sales reps will be wasting more of their time on wrong numbers or numbers that won’t pick up. With emails, you might think that it’s no big deal, but your open rates and other KPIs will be distorted based on your “dirty” list. All of these costs add up quickly, contributing to the $600 billion annual data problem that U.S. companies face.
However, let’s flip the situation: if your data quality improvement strategy is on point, then you'll be able to:
- Get Facebook leads at lower costs than your competition
- Get more ROI from each direct mail, phone call, or email campaign you execute
- Show C-suite executives better results, making it more likely your ad spend will get increased
All in all, in today’s digital world, having high-quality data is what makes the difference between the leaders of the pack and the “also-rans".
The Consequences Of Bad Data Quality Control
Bad data quality control can impact every aspect of an organization, including:
- How much do your marketing campaigns cost and how effective they are
- How accurately you are able to understand your customers
- How quickly you can turn prospects into leads into sales
- How accurately you can make business decisions
According to recent information published by Gartner, poor data quality costs businesses an average of $12.9 million a year. This not only translates into a loss in revenue but also to poor decision-making, which can lead to many intangible costs.
The intangible costs
We can’t examine the intangible costs directly. However, we can use our intuition and imagination in this area.
Let’s say that you’re striving to create a data-driven culture at your company. You’re spearheading the effort and currently conducting a pilot program to show the ROI of making data-driven decisions using business intelligence and analytics. If your data isn’t high-quality, you’ll run into many problems showing other people the benefits of BI. If you blame the data quality “after the fact”, your words will just sound like excuses.
However, if you address things upfront and clarify to your colleagues that high quality is absolutely necessary and is the cornerstone of getting ROI from data, you’ll be in a much better position.
One huge intangible cost: bad decisions
Maybe you’re not trying to convince others of the importance of data-driven decision-making. Maybe your company already utilizes analytics but isn’t giving due diligence to data quality control. In that case, you can face an even bigger blowup: making costly decisions based on inaccurate data.
As a big data expert, Scott Lowe states, maybe the worst decisions are made with bad data: which can lead to greater and more serious problems in the end. He would rather make a decision listening to his guts than risk making one with bad data.
For example, let’s say you have an incorrect data set showing that your current cash flows are healthy. Feeling optimistic, you expand operations significantly. Then, a quarter or two later, you run into cash flow issues, and suddenly it’s hard to pay your vendors (or even your employees). Higher-quality data could prevent this kind of disastrous situation.
3 Sources Of Low-Quality Data
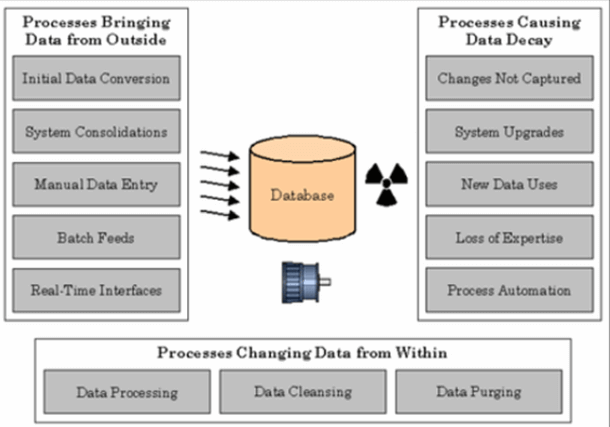
Image source: TechTarget
We’ve just gone through how to clean data that may not be accurate. However, as the saying goes, an ounce of prevention is worth a pound of cure. With that in mind, here are some of the origins of low-quality data so that you can be mindful about keeping your records accurate as time passes. Remember: keeping your data high-quality isn’t a one-time job. It’s a continual process that never ends.
Source #1: Mergers and acquisitions
When two companies join together somehow, their data tags along into this new working relationship. However, just like when two people with children from prior marriages form a new relationship, things can sometimes get messy.
For example, it’s very possible, and even probable, that your two companies use entirely different data systems. Maybe one of you has a legacy database, while the other has updated things. Or you use different methods of collecting data. It’s even possible that one partner in the relationship simply has a lot of incorrect data.
Data expert Steve Hoberman gives an example of mergers causing difficulty. He writes that when these two databases disagree with each other, you must set up a winner-loser matrix that states which database's entries are to be regarded as “true”. As you might expect, these matrices can get exceedingly complex: at some point, "the winner-loser matrix is so complex that nobody really understands what is going on", he says. Indeed, the programmers can start arguing with business analysts about futilities and "consumption of antidepressants is on the rise”.
Action Step: In the event of a planned merger or acquisition, make sure to bring the heads of IT to the table so that these kinds of issues can be planned for in advance -before any deals are signed.
Source #2: Transitioning from legacy systems
To a non-technical user, it may be hard to understand the difficulties inherent in switching from one operating system to another. Intuitively, a layman would expect that things are “set up” so that transitions are easy and painless for the end user. This is definitely not in line with reality.
Many companies use so-called “legacy systems” for their databases that are decades old, and when the inevitable transition time comes, there’s a whole host of problems to deal with. This is due to the technical nature of the data system itself. Every data system has three parts:
- The database (the data itself)
- The “business rules” (how the data is interpreted)
- The user interface (how the data is presented)
These distinct parts can create distinct challenges during data conversion from one system to another. As Steve Hoberman writes, the center of attention is the data structure during the data conversion. But this is a failing approach, as the business rule layers of the source and destination are very different. The converted data is inevitably inaccurate for practical purposes even though it remains technically correct.
Action step: When transitioning from a legacy system to a newer one, it’s not enough that your transition team is an expert in one system or the other. They need to be experts in both to ensure that the transition goes smoothly.
Source #3: User error
This problem will probably never go away because humans will always be involved with data entry, and humans make mistakes. People mistype things regularly, and this must be accounted for. In his TechTarget post, Steve Hoberman relates a story of how his team was in charge of “cleansing” a database and correcting all of the wrong entries.
You would think that data-cleansing experts would be infallible, right? Well, that wasn’t the case. As Mr. Hoberman states, “Still, 3% of the corrections were entered incorrectly. This was in a project where data quality was the primary objective!”
Action step: Create all the forms that your company uses as easy and straightforward to fill out as possible. While this won’t prevent user error entirely, it will at least mitigate it.
Data Quality Solutions & Tools: Key Attributes
So far, we have offered a detailed guide to the data quality management framework, with its benefits, consequences, examples, and more. Now, you might be wondering, how do I make all of this happen? The answer is with big data quality management tools. There are many solutions out there that can help you assess the accuracy and consistency of your information. To help you choose the right one, here we list the top 5 features you should look for in any DQM software worth its salt.
- Connectivity: To be able to apply all quality rules, DQM software should ensure integration and connectivity as a basis. This means being able to easily connect data coming from multiple sources such as internal, external, cloud, on-premise, and more.
- Profiling: Data profiling enables users to identify and understand quality issues. A tool should be able to offer profiling features in a way that is efficient, fast, and considers the DQM pillars.
- Data monitoring and visualization: To be able to assess the quality of the data, it is necessary to monitor it closely. For this reason, software should offer monitoring capabilities using interactive data visualizations in the shape of online dashboards.
- Metadata management: Good data quality control starts with metadata management. These capabilities provide the necessary documentation and definitions to ensure that data is understood and properly consumed across the organization. It answers the who, what, when, where, why, and how questions of data users.
- User-friendliness and collaboration: Any solution that requires the use of data in today's modern context should be user-friendly and enable collaboration. As mentioned time and time again throughout this post, there are many key players in a corporate data quality management system, and they should be able to share key definitions, specifications, and tasks in an easy and smart way.
Emerging Data Quality Trends To Watch
If you’ve gotten to this point, then you should be aware of the importance of working with clean and secure information. And you are not alone. According to recent reports, 82% of businesses believe quality concerns represent a barrier to their data integration projects. Making DQM systems a key tool to ensure the resources spent on data analytics don’t go to waste.
But how are the different industries responding to these quality threats? What new technologies are coming up to ensure organizations can work with quality information? Below, we will discuss some of the current trends in the data quality industry to help you get on the right path.
Artificial intelligence & machine learning
It might not come as a surprise that enterprises are now relying on powerful artificial intelligence and machine learning technologies to support their analytical quest. These technologies have already penetrated the industry with multiple tools, including natural language processing, computer vision, and automated processing of large volumes of data, among others. This is because, today, developing and deploying AI and ML models is easy and not expensive. Plus, the models keep learning and developing on their own, allowing businesses to efficiently automate tasks like data classification and quality control.
Automation
Expanding on the previous trend, manually extracting, transforming, and loading data is the enemy of quality. That is why automation has remained one of the biggest trends in the industry for the past few years, and not just when it comes to data quality but the entire data management process. Automation ensures complex, monotonous tasks are completed with efficiency and accuracy with the help of AI and ML. Thanks to these technologies, businesses can automate several tasks, including data discovery and extraction, and perform automatic quality checks to ensure they are working with the highest quality information.
Increased focus on trust architecture and security
As mentioned earlier, implementing a data governance plan has become one of the greatest practices to ensure data is compliant, secure, and efficient. This is especially true considering how complex business data is becoming from a management and regulatory perspective, turning governance initiatives into a mandatory practice rather than a choice.
To help boost their governance initiatives, organizations have started to invest in a new approach called “trust architecture”, which allows them to build and maintain stakeholders' trust in their data-driven products and services. McKinsey’s technology trends report for 2023 shows digital-trust technologies have increased their investment to $47 billion in 2022. That being said, a good trust architecture depends mostly on data quality. Therefore, automated data quality management tools will continuously increase their focus on offering governance and trust solutions to drive data quality and security in an automated environment.
Data Democratization
Even though the value of data is more than recognized, there are still many organizations that fail in their analytical efforts due to a lack of literacy and accessibility across areas and departments. That is why democratizing data has become such an important aspect of the process. Ensuring all employees have the knowledge but, most importantly, the trust they need to use data for their decision-making process is very important.
This is no different when it comes to ensuring quality. The grounds for a successful DQM framework rely mostly on full organizational adoption and keeping every relevant stakeholder responsible for ensuring data quality. In that sense, using Low-code/No-code apps has become a great solution. These tools can be used by anyone without any technical knowledge, empowering them to check their data independently, saving the IT team a lot of time and the business a lot of money
To Conclude...
We hope this post has given you the information and tools you need to keep your data high-quality. We also hope you agree that data quality management is a crucial process for keeping your organization competitive in today’s digital marketplace. While it may seem to be a real pain to maintain high-quality data, consider that other companies also feel like DQM is a huge hassle. So, if your company is the one that takes the pains to make it sound, you’ll automatically gain a competitive advantage in your market. As the saying goes, “if it were easy, everyone would be doing it.”
DQM is the precondition to creating efficient business dashboards that will help your decision-making and bring your business forward. To start building your own company dashboards and benefit from one of the best solutions on the market, start your 14-day free trial here!