Top 10 Analytics And Business Intelligence Buzzwords For 2024

Business Intelligence Buzzwords 2024
Business intelligence has undergone many changes in the last decade. Each year, we hear about buzzwords that enter the community, language, and market and drive businesses and companies forward. That’s why we have prepared a list of the most prominent business intelligence buzzwords that will dominate in 2024.
Without further ado, let’s get started.
1. Generative AI
1. Generative AI
If you were on the internet at all in 2023, then you must have heard about generative artificial intelligence (genAI) at least once. The technology, which gained massive popularity thanks to tools like ChatGTP, is a type of artificial intelligence that analyses massive amounts of data to generate images, videos, audio, text, and 3D models based on human input. It uses deep learning and large language models to generate unique pieces of content that imitate human creativity, and it is expected to account for 20% of global AI spending by 2032.
As of 2023, the development and popularity of genAI models have been linked mostly to consumers. However, in 2024, we can expect to see more enterprise use cases being developed as more industries realize the value of the technology.
In a business context, genAI will change how companies use artificial intelligence, shifting from tasks like pattern recognition and forecasting to generating new data that can drive strategic and operational performance. In fact, Gartner predicts that by 2025, 10% of all data will be AI-generated, which shows the impact generative AI can have on the way we do business today. For example, companies can use genAI to improve customer experiences through the use of chatbots and virtual assistants, others can use it to boost employee productivity through AI-based code generation or automated reporting, and others can use it to optimize key processes through data augmentation or supply chain optimization.
It is important to note that genAI is not free of criticism. While research shows that 67% of senior IT leaders will prioritize generative AI for their business, there are big ethical concerns regarding this technology. 73% of said IT leaders cite security concerns linked to this technology, while 73% of them are concerned about biased outcomes. For example, there are reported cases in which people use ChatGTP to spread false information, making it look like it came from a reliable source.
The truth is generative artificial intelligence is in its developing stage, and there are still a lot of questions and challenges that need to be tackled to make it a fully trustable tool. Even so, we can expect this buzzword to become even more popular in the coming years.
2. Decision Intelligence
Continuing our list of data buzzwords for 2024, decision intelligence is certainly one worthy point to include since businesses of all sizes must embrace the power of generating actionable insights and making better decisions through data and analysis. In recent years, companies have adopted solutions, such as self-service BI, that foster the decision intelligence roadmap: observe, investigate, model, contextualize, and execute. This model has become increasingly important in today's competitive environment, where countless pieces of information are being generated, but the quality of decision-making can suffer.
But let's get back to basics. Decision intelligence offers a "structure for organizational decision-making and processes" with the help of machine learning algorithms. It's a field that also includes methods such as descriptive, diagnostic, and prescriptive analytics. Moreover, it contains 3 types of models: human-based decisions, machine-based, and hybrid decisions, each with its own set of characteristics, with data being the core force. But, as we all know it, humans cannot process so much data on a daily basis and expect positive business outcomes. That's why artificial intelligence supports managers on their path to successful data-driven decision-making and helps them to make accurate, fast, and fully informed business decisions.
In practice, decision intelligence is one of the business words that has evolved and will help companies in different industries. For example, a bulk carrier in the US used IBM to optimize its logistics processes and transportation, resulting in millions of dollars saved. The smart decision-processing method enabled the company to save unnecessary driving and optimize routes in real-time. Another example comes from the banking industry, where decision intelligence helped transform their telecommunication technology into a more advanced one and saved countless dollars. Their database was extremely large, and the updates would cause a chain of events that could affect many other parts of their system. Thanks to the cause-and-effect link of decision intelligence models, the bank managed to upgrade its systems seamlessly.
3. Data Fabric
The number of sources from which businesses gather data is increasingly growing. As this grows, so does the need for faster access to information that is distributed in several locations. That’s where data fabric comes into the picture to establish itself as one of the most important BI buzzwords of 2024.
Gartner defines data fabric as a “design concept that serves as an integrated layer of data and connecting processes.” Putting it in simpler words, data fabric is a data management architecture that aims to help organizations access and connect data from multiple types, locations, and sources in order to close the breach between the data available and the knowledge extracted from it. This allows businesses to access their data faster and in a structured way, from collecting, ingesting, and integrating. The data can also be shared with internal or external applications and used for a number of scenarios, such as product development, sales and marketing optimization, and more advanced processes, such as forecasting.
The main reason why data fabric will be so useful for businesses in 2024 is that it will help them extract the full potential out of the information available. Studies say that organizations only analyze 12% of their available data, meaning 88% of valuable information is left unseen. With a data fabric strategy in place, from average business users to data scientists will have fast and compliant access to all the needed data for an improved decision-making process. Through this, businesses can simplify data management and governance and automate several processes in a complex multi-cloud environment while cutting costs and risks.
The goal of data fabric is simple. Providing a single environment for all the available data from any location ensures an optimized and unified data management process. It's about leveraging people and technology to maximize the value of their information. Allowing them to produce more engaging customer experiences, better products, and services, and increase overall business efficiency.
4. Data Mesh Architecture
Moving on with our list of data analysis buzzwords, we will now dive into the data mesh architecture. This concept is defined as a “cultural and organizational shift that emphasizes the authority of localized data management.” It promotes a distributed system that enables the standard business user to access and consume business data upon need.
The concept gained notoriety after many companies struggled with their central data team not having enough time to prepare the data, learn from it, and extract insights to be sent to specific departments. When the process was done, the data might not be valuable anymore. This is a big problem in today’s landscape, as making real-time agile decisions is key to staying competitive. As a solution, companies generated “domain teams” composed of employees from different departments to analyze the data as soon as it is prepared by the data team. Unfortunately, this approach also generated bottlenecks, especially as the organization and the amount of data being collected grew.
A data mesh architecture comes as the ultimate solution to these problems as it shifts the responsibility from the data team to specific domain teams. This means people from different areas, including marketing, HR, sales, finance, and more, have the ability to access, manage, and analyze the data on their own, as well as perform cross-domain analysis, following governance practices. This “domain ownership principle” says that the different domain teams need to access the data and transform it into data products that meet specific needs and that can be easily accessed and read by data consumers.
If this sounds a bit similar to data fabric, which we discussed above, it's because both concepts have similarities. They are both data architectures that promote an integrated and agile data management process that involves the entire organization. However, they differ in their approach. A data mesh focuses on decentralization and looking at the data as a product. It helps optimize and manage data-related processes and people. On the other hand, data fabric offers centralized and unified access to all the data, and it is used to tackle metadata complexity. In short words, a data mesh promotes domain-specific data ownership, and a data fabric is a “layer” that provides a single source of truth for all business data.
Data mesh is definitely a buzzword that we will hear more about in the coming years, with big companies like Airbnb, Netflix, and Walmart already adopting it.
5. Predictive & Prescriptive Analytics
Predictive Analytics: What could happen?
We mentioned predictive analytics in our business intelligence trends article, and we will stress it here as well since we find it extremely important for 2024. Predictive analytics is the practice of extracting information from existing data sets in order to forecast future probabilities. Applied to business, it is used to analyze current and historical data in order to better understand customers, products, and partners and to identify potential risks and opportunities for a company. Undoubtedly, it’s a big technological advancement and one of the big statistics keywords, but the extent to which it is believed to be already applied is vastly exaggerated.
The commercial use of predictive analytics is a relatively new thing. The accuracy of the predictions depends on the data used to create the model. For instance, if a model is created based on the factors inherent in one company, it doesn’t necessarily apply to a second company. The same may be true about a model for one year compared to the next year within the same company. Approaches need to take this dynamic nature into mind. Moreover, as most predictive analytics capabilities available today are in their infancy, they have simply not been used for long enough by companies on enough data sources. Hence, the material on which to build predictive models was quite scarce.
Last but not least, there is the human factor again. The psychological patterns behind why people make decisions cannot be boiled down to simple logic and are often complex and unpredictable.
Nevertheless, predictive analytics has been steadily building itself into a true self-service capability used by business users who want to know what the future holds and create more sustainable data-driven decision-making processes throughout business operations, and 2024 will bring more demand and usage of its features.
Prescriptive Analytics: What should we do?
Prescriptive analytics takes the next step but also analyzes and includes action. These analytics use optimization and simulation algorithms to advise on possible outcomes and answer: “What should we do?” This allows users to “prescribe” a number of different possible actions to undertake and guide them toward a solution. Prescriptive analytics attempts to quantify the effect of future decisions in order to advise on possible outcomes before the decisions are actually made. At their best, prescriptive analytics predicts not only what will happen but also why it will happen. The analytics also provide recommendations regarding actions that will take advantage of the predictions. We are excited to see how prescriptive analytics moves forward in 2024.
Try our BI software for a 14-day free trial & benefit from smart analytics!
6. Digital Automation
The umbrella term of digital automation focuses on the rise of intelligent technologies to impact businesses across industries, providing automated processes that make big data and analytical analysis easier to utilize and comprehend and, consequently, gain valuable insights—integrating artificial intelligence and intelligent automation tools to solve business challenges while increasing productivity will become a pivotal point in the next phase of digital transformation.
The importance of speed in businesses is not the latest news but the tools and means to gain proper data, be it while compiling a management report, determining which KPI examples to research, study, and choose, or which AI automation process to leverage in a specific industry, will certainly affect businesses of all sizes in 2024.
Taking advantage of artificial intelligence and machine learning while using neural network alerts and pattern recognition alerts can bring automation to a business on a speedy, valuable, and sustainable level. And since a giant like MIT is investing in a new college focused on AI worth $1 billion, we will keep digital automation as one of the business intelligence buzzwords to look out for in 2024.
7. Emotional Intelligence BI
Historically, when we think about AI-driven technologies, we think about numbers, data, technology, and innovations. However, what these technologies still lack is the ability to feel and recognize emotions, a fundamental aspect that could be a game changer for organizations that rely on these tools. That is where our next BI buzzword comes in.
Emotional intelligence (EI) refers to the ability to recognize, understand, and express emotions, such as self-awareness, empathy, and self-regulation, among many others. These capabilities are often attributed to humans. However, the latest AI innovations aim to allow machines to have emotional intelligence and use it to drive better outcomes.
There are many industries that could benefit from this innovation, including healthcare, education, customer service, human resources, and marketing, just to name a few. The truth is that giving machines the power to understand emotions can help businesses understand their clients better and offer targeted promotional campaigns, better customer service, and improve the overall customer journey. It can also help managers understand employees better to drive productivity. Making emotional intelligence a key business intelligence asset.
That being said, just like many other AI-related innovations, there is a range of ethical considerations when it comes to developing this kind of technology. The biggest one is data privacy and security, as machines would need to access personal data to be able to learn and respond to emotions. Ethical misuse is another challenge, as AI systems must be properly trained to avoid using emotions to manipulate or make biased decisions.
As a solution, experts suggest establishing clear guidelines and regulations to govern the development and implementation of EI in machines, ensuring that the systems are properly trained with security and privacy considerations and in direct collaboration with humans.
In 2024 and beyond, we can expect the topic of emotional intelligence linked to BI and AI to become exponentially relevant as more and more businesses invest in developing systems to drive decision-making and growth.
8. Mobile Analytics
Mobile usage is becoming an increasing factor in BI. With more vendors each year that offer mobile solutions within their software, companies are also starting to implement mobile data management, and 2024 will increase even more. In fact, the market size is expected to reach $27,598.61 million by 2031. That proves that this is one of the analytics buzzwords that will continue its growth and market expansion. While North America accounted for the major share in the mobile analytics market, Europe and the Asia Pacific will witness lucrative growth as well, states Research Nester.

Mobility is key to growth, which is unquestionable, and companies need to realize how to implement mobile solutions that they can fully take advantage of. In the business intelligence world, mobile analytics means providing users with the ability to quickly access their data on the go, no matter the location, and with the only requirement of an Internet connection. Like this, users are empowered to leverage their data from wherever they are with the same features they would have on the desktop, making mobile analytics an added value to businesses across the globe. Giants such as Amazon, Google, IBM, and Yahoo have already been identified as key players, confirming the importance of mobile in today’s competitive digital world.
Why mobile is becoming pervasive can be simply explained by the rapid expansion and implementation of tablets, laptops, and mobile devices on which users can access analytics easily without the need to be physically present in a company. Anyone can access their analytics data with a business account and simply log in to a cloud service, for example, and gain instant insights on the performance, numbers, online dashboards, and reports. The most common use cases for mobile BI are through a webpage where users just need to log in via their personal account, an HTML5 site that works similarly to a web page but with some improvements, such as not relying on proprietary standards. And lastly, one of the most complicated and expensive ones is via a native app that can be downloaded into any mobile device.
Mobile analytics is becoming a huge advantage for companies since they have the opportunity to make faster decisions, answer business questions immediately, and conduct an instant analysis of data while providing access to everyone who needs it. In 2024, mobile will only expand, and we have yet to see exactly how much.
9. Self-service BI
The image of SQL experts, data scientists, and system analysts working on data to extract the maximum possible is becoming obsolete. BI already helped simplify data analysis for many business users, and the widespread adoption of self-service online BI democratized data within organizations. By using technologies such as drag-and-drop interfaces and interactive visualizations in the shape of business dashboards, self-service BI opens the analytical doors to anyone who wants to use data for their decision-making process with no training needed. You can see a self-service BI interface in this example:
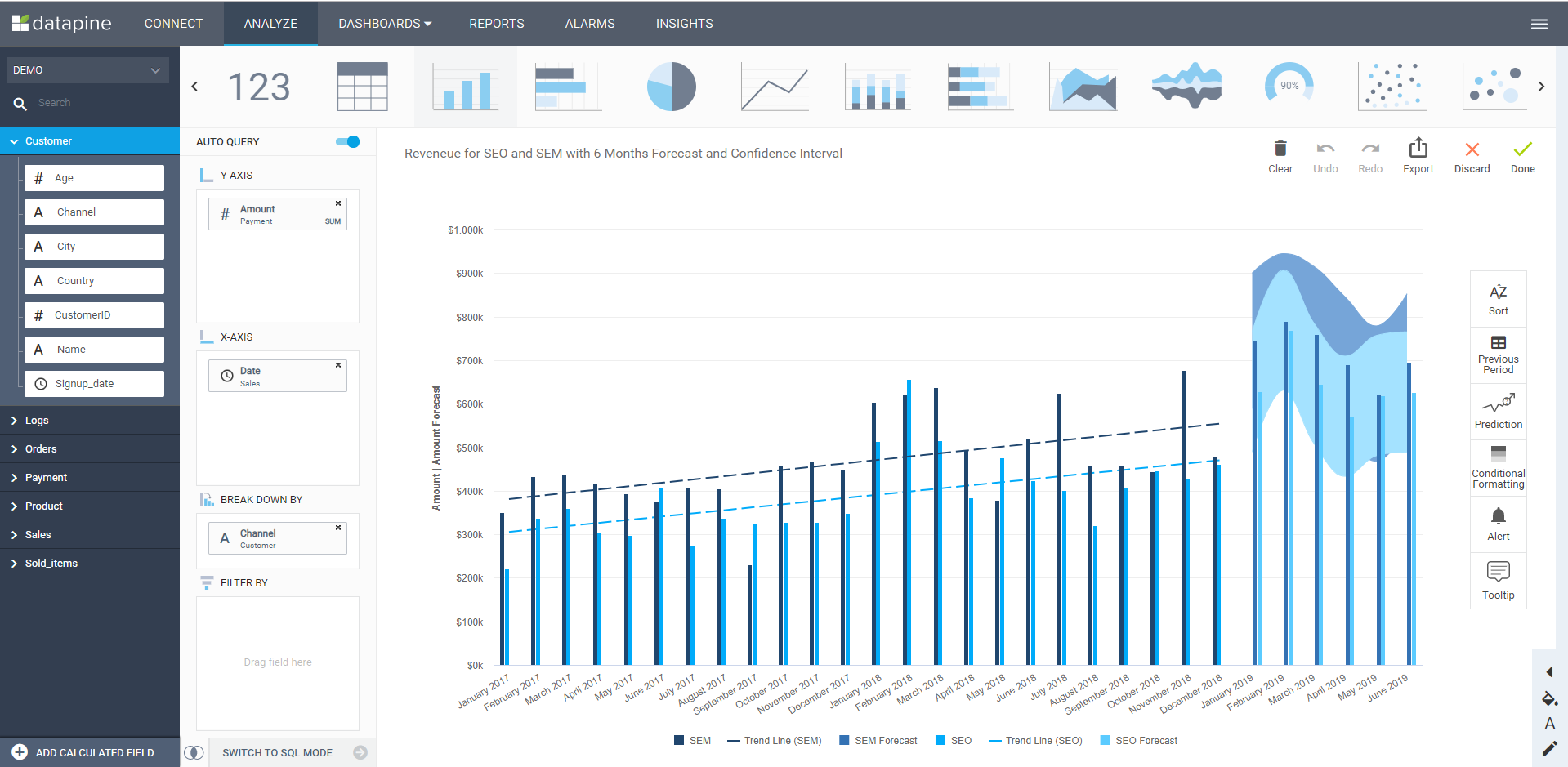
**click to enlarge**
Automated business intelligence increases that process and will make BI accessible to anyone and everyone: it will no longer be restricted to small groups of specialized people, and “citizen data scientists” will become the norm. Modern BI means less specialization, more automation, and an easy approach to data analytics for everyone.
By creating more streamlined processes to dig deep into business data, productivity will increase, and it will also help in overcoming the skills gap. Business intelligence will hence become more accessible, democratizing data in 2024 more than ever before.
User independence and self-sufficiency are at the heart of self-service BI. The usage of information within a company will bring even more decentralization of data and accessibility for everyone. But the level of decentralization also depends on the requirements and user roles – while it can help fulfill various tasks, it certainly needs to be considered which ones and for whom. In 2024, we will see more vendors taking the role of providing data analysis tools that can be used by everyone in the company – analysts, departmental managers, or average business users.
Before the self-service approach in BI, companies needed to hire an IT or data science team to perform complex analyses and export data reports. This became a huge setback as the need for more agile reporting and analysis increased. With self-service solutions, users from all levels of knowledge are empowered to work with data, generate an online report with just a few clicks, and extract actionable insights to boost performance. In the next few years, the level of self-service is expected to evolve, and experts predict that next year, the significance will only rise. This is one of the data buzzwords for 2024 that we will be hearing more about since companies are looking for ways to clean their data in the most efficient way possible.
10. Natural Language Processing (NLP)
Natural language processing is transforming business intelligence at a remarkable pace. And not just NLP but all of its manifestations, such as natural language understanding (NLU), natural language generation (NLG), or natural language interaction (NLI). Each has its foundation in artificial intelligence solutions developed to make human-computer interaction easier and more efficient. NLP is a developing field that catches the attention of experts from all over the world. In fact, in July 2024, the International Conference on Natural Language Processing and Computational Linguistics will be conducted in Yinchuan, China. There, it’s expected that experts from all over the world will share their knowledge, findings, and projects regarding NLP.
But, before we continue, what is really NLP? Essentially, Natural Language Processing is a subfield of computer science and AI that allows computers to understand any form of human communication, be it text or spoken words. The basics lay within complex computational and mathematical methods within the machine learning domain, and the development started almost 50 years ago. Traditionally, NLP has seen the most success in facilitating text analysis, but the applications of NLP will become even more accessible to the average business users and their everyday utilization of BI.
Business intelligence is changing how we interact with natural language processing, especially in large datasets. It enables non-technical users to perform complex analyses with the help of software and without the special intervention of the IT team. NLP helps reveal patterns that could otherwise stay uncovered, so it’s unsurprising that the industry is expected to grow to $29.19 billion by the end of 2024. The communication capacity of cognitive computing will not stall but is only set to grow, and this will be one of the data analytics buzzwords we will hear even more about in 2024.
Some of the simple examples of NLP usage and adoption are autocorrecting, machine translation, bots, virtual assistants, and, not to forget, giants such as Siri or Alexa. In business intelligence, one of the popular usages is in the form of opinion mining. Big brands use NLP techniques to perform social media monitoring to help in the analysis and reflect customer sentiments. For example, to measure whether the reception of a new product is good or bad. Another common use when it comes to data analysis is to clean the data by using a method called stemming. Essentially, this method uses algorithms to reduce words to their most basic form. For example, if your dataset has the words changing, changes, and changer, they would all be turned into the simple form change. This keeps the analysis process clearer and faster. All things considered, NLP will certainly be a buzzword in 2024, continuing its adoption in many industries and providing additional value to businesses of all sizes.
Try our BI software for a 14-day free trial & benefit from smart analytics!
The Top 10 BI Buzzwords For 2024!
We hope you enjoyed our list of business intelligence and analytics buzzwords for 2024. Without a doubt, the coming year will see these words developing and changing the BI scenery. To summarize, we bring you the list we have discussed:
- Generative AI
- Decision Intelligence
- Data Fabric
- Digital Automation
- Data Mesh Architecture
- Predictive & Prescriptive Analytics
- Emotional Intelligence BI
- Mobile Analytics
- Self-service BI
- Natural language processing (NLP)
To get you started on your own business intelligence adventure, you can try our software for a 14-day trial completely free!